在构建模型时,调参是极为重要的一个步骤,因为只有选择最佳的参数才能构建一个最优的模型。但是应该如何确定参数的值呢?所以这里记录一下选择参数的方法,以便后期复习以及分享。
<强>(除了贝叶斯优化等方法)其它简单的验证有两种方法:
1,通过经常使用某个模型的经验和高超的数学知识。
2,通过交叉验证的方法,逐个来验证。
很显然我是属于后者所以我需要在这里记录一下
我使用是cross_val_score方法,在sklearn中可以使用这个方法。交叉验证的原理不好表述下面随手画了一个图:
(我都没见过这么丑的图)简单说下,比如上面,我们将数据集分为10折,做一次交叉验证,实际上它是计算了十次,将每一折都当做一次测试集,其余九折当做训练集,这样循环十次。通过传入的模型,训练十次,最后将十次结果求平均值。将每个数据集都算一次
1:交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。
2:还可以从有限的数据中获取尽可能多的有效信息。
我们如何利用它来选择参数呢?
我们可以给它加上循环,通过循环不断的改变参数,再利用交叉验证来评估不同参数模型的能力,最终选择能力最优的模型。
<强>下面通过一个简单的实例来说明:(虹膜鸢尾花)
从sklearn导入数据集#自带数据集
从sklearn。model_selection进口train_test_split cross_val_score #划分数据交叉验证
从sklearn。邻居进口KNeighborsClassifier #一个简单的模型,只有K一个参数,类似K - means
进口matplotlib。pyplot作为plt
虹膜=datasets.load_iris() #加载sklearn自带的数据集
X=虹膜。数据#这是数据
y=虹膜。目标#这是每个数据所对应的标签
train_X、test_X train_y test_y=train_test_split (X, y, test_size=1/3, random_state=3) #这里划分数据以1/3的来划分训练集训练结果测试集测试结果
k_range=范围(31)
cv_scores=[] #用来放每个模型的结果值
在k_range n:
然而,=KNeighborsClassifier (n) #资讯模型,这里一个超参数可以做预测,当多个超参数时需要使用另一种方法GridSearchCV
成绩=cross_val_score(资讯、train_X train_y,简历=10,得分=白既沸浴?#简历:选择每次测试折数精度:评价指标是准确度,可以省略使用默认值,具体使用参考下面。
cv_scores.append (scores.mean ())
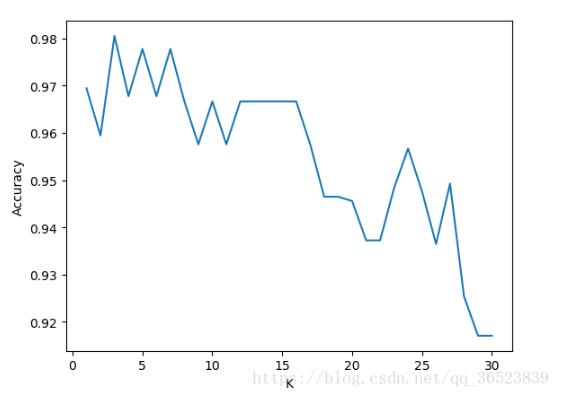
plt.plot (k_range cv_scores)
plt.xlabel (“K”)
plt.ylabel(精度)#通过图像选择最好的参数
plt.show ()
best_knn=KNeighborsClassifier (n_neighbors=3) #选择最优的K=3传入模型
best_knn.fit (train_X train_y) #训练模型
print (best_knn.score (test_X test_y) #看看评分
最后得0.94分
关于cross_val_score的得分参数的选择,通过查看官方文档后可以发现相关指标的选择可以在这里找的到:文档。
这应该是比较简单的一个例子了,上面的注释也比较清楚,如果我表达不清楚可以问我。
废话不多说,上代码吧!
进口操作系统
进口numpy np
熊猫作为pd导入
从sklearn导入数据集
从sklearn进口预处理
从sklearn进口的邻居
从sklearn。discriminant_analysis进口LinearDiscriminantAnalysis
从sklearn进口支持向量机
从sklearn。整体进口RandomForestClassifier
从sklearn。model_selection进口train_test_split
从sklearn。model_selection进口StratifiedKFold
从sklearn。linear_model进口LogisticRegression
从sklearn。model_selection进口GridSearchCV
从进口时间
从sklearn。naive_bayes进口MultinomialNB
从树sklearn进口
从sklearn。整体进口GradientBoostingClassifier
#读取sklearn自带的数据集(鸢尾花)
def getData_1 ():
虹膜=datasets.load_iris ()
X=虹膜。数据#样本特征矩阵,150 * 4矩阵,每行一个样本,每个样本维度是4
y=虹膜。目标#样本类别矩阵,150维行向量,每个元素代表一个样本的类别
#读取本地excel表格内的数据集(抽取每样类60%本组成训练集,剩余样本组成测试集)
#返回一个元祖,其内有4个元素(类型均为numpy.ndarray):
#(1)归一化后的训练集矩阵,每行为一个训练样本,矩阵行数=训练样本总数,矩阵列数=每个训练样本的特征数
#(2)每个训练样本的类标
#(3)归一化后的测试集矩阵,每行为一个测试样本,矩阵行数=测试样本总数,矩阵列数=每个测试样本的特征数
#(4)每个测试样本的类标
#【注】归一化采用“最大最小值”方法。
def getData_2 ():
fPath=' D: \分类算法\ binary_classify_data.txt '
如果os.path.exists (fPath):
data=https://www.yisu.com/zixun/pd.read_csv (fPath头=None, skiprows=1,名字=[‘class0’,‘pixel0’,‘pixel1’,‘pixel2 ', ' pixel3 '])
X_train1、X_test1 y_train1 y_test1=train_test_split(数据、数据(“class0”) test_size=0.4, random_state=0)
min_max_scaler=preprocessing.MinMaxScaler() #归一化
X_train_minmax=min_max_scaler.fit_transform (np.array (X_train1))
X_test_minmax=min_max_scaler.fit_transform (np.array (X_test1))
返回(X_train_minmax np.array (y_train1) X_test_minmax, np.array (y_test1))
其他:
print(“没有这样的文件或目录!”)
#读取本地excel表格内的数据集(每类随机生成K个训练集和测试集的组合)
#【K的含义】假设一共有1000个样本,10 K取,那么就将这1000个样本切分10份(一份100个),那么就产生了10个测试集
#对于每一份的测试集,剩900余个样本即作为训练集
#结果返回一个字典:键为集合编号(1火车,1 trainclass 1测试1 testclass, 2火车,2 trainclass 2测试,2 testclass…),值为数据
#其中1训练和测试为随机生成的第一组训练集和测试集(1 trainclass和1 testclass为训练样本类别和测试样本类别),其他以此类推
def getData_3 ():
fPath=' D: \ \分类算法\ \ binary_classify_data.txt”
如果os.path.exists (fPath):
#读取csv文件内的数据,
dataMatrix=np.array (pd.read_csv (fPath头=None, skiprows=1,名字=[‘class0’,‘pixel0’,‘pixel1’,‘pixel2 ', ' pixel3 ']))
#获取每个样本的特征以及类标
rowNum colNum=dataMatrix。形状[0],dataMatrix.shape [1]
sampleData=https://www.yisu.com/zixun/[]
sampleClass=[]
因为我在范围(0,rowNum):
tempList=列表(dataMatrix [i:])
sampleClass.append (tempList [0])
sampleData.append (tempList [1]):
sampleM=np.array (sampleData) #二维矩阵,一行是一个样本,行数=样本总数,列数=样本特征数
classM=np.array (sampleClass) #一维列向量,每个元素对应每个样本所属类别
#调用StratifiedKFold方法生成训练集和测试集
skf=StratifiedKFold (n_splits=10)
setDict={} #创建字典,用于存储生成的训练集和测试集
数=1
在skf trainI,包括。分割(sampleM classM):
trainSTemp=[] #用于存储当前循环抽取出的训练样本数据
trainCTemp=[] #用于存储当前循环抽取出的训练样本类标
testSTemp=[] #用于存储当前循环抽取出的测试样本数据
testCTemp=[] #用于存储当前循环抽取出的测试样本类标
#生成训练集
trainIndex=列表(trainI)
t1的范围(0,len (trainIndex)):
trainNum=trainIndex (t1)
trainSTemp。追加(列表(sampleM [trainNum:]))
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null





