
首先看下面代码的执行情况:
<前>=(1、2、3) 打印(“=% s ' %) #一个=(1、2、3) b=一个 打印(" b=% s ' % b) # b=(1、2、3) a.append(4) #对进行修改 打印(“=% s ' %) #一个=(1、2、3、4) 打印(" b=% s ' % b) # b=(1、2、3、4) b.append(5) #对b进行修改 打印(“=% s ' %) #一个=[1、2、3、4、5) 打印(" b=% s ' % b) # b=[1、2、3、4、5)上面的代码比较简单,定义了一个变量,它是一个数值(1、2、3)的列表,通过一个简单的赋值语句b=定义变量b,它同样也是数值(1、2、3)的列表。
问题是:如果此时修改变量,对b会有影响吗?同样如果修改变量b,对一个又会有影响吗?
从代码运行结果可以看的出,无论是修改b还是修改一个(注意这种修改的方式,是用附加,直接修改原列表,而不是重新赋值),都另一方都是有影响的。
当然这个原因其实很好理解,变量一指向的是列表(1、2、3)的地址值,当用=进行赋值运算时,b的值也相应的指向的列表(1、2、3)的地址值。在python中,可以通过id(变量)的方法来查看地址值,我们来查看下a, b变量的地址值,看是不是相等:
<前> #注意,不同机器上,这个值不同,但只要a, b两个变量的地址值是一样的就能说明问题了 打印(id (a)) # 4439402312 打印(id (b)) # 4439402312所以原理如下图所示:
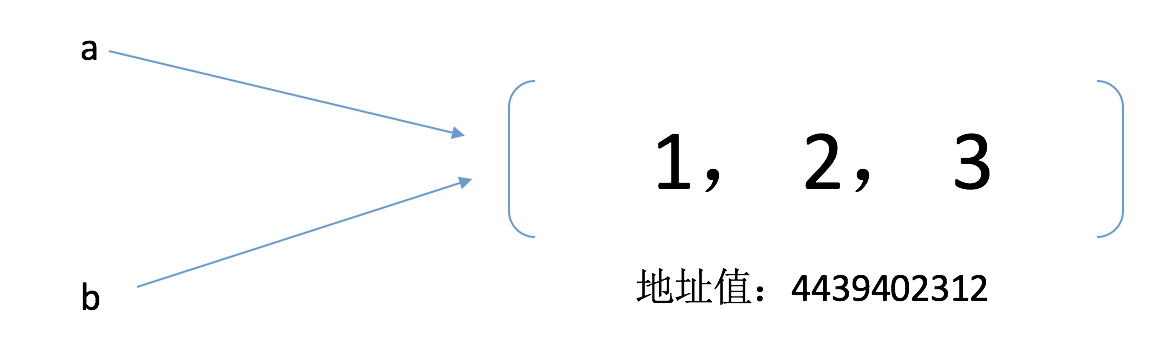
因此,只要是在地址值:4439402312上的列表进行修改的话,a, b都会发生变化。(注意我这里说的修改,是在地址值为:4439402312上的列表进行的修改,而不说对变量一进行修改,因为对变量一的修改方式有两种,本文结尾会解释为什么不说对变量一进行修改),,所以我们便引出了以下概念:
对于这种是将引用进行拷贝赋值给另一个变量的方式(即拷贝的是地址值),我们称之为浅拷贝。
python中实现深拷贝的方式很简单,只需要引入复制模块,调用里面的deepcopy()的方法即可,示例代码如下:
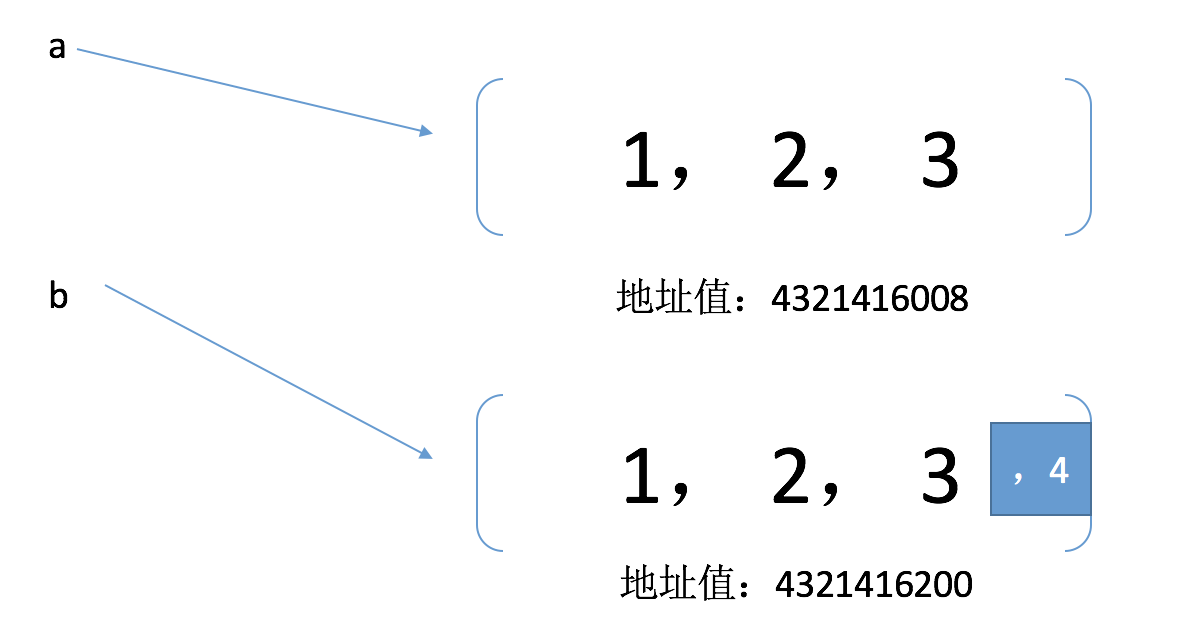
<前> 进口复制=(1、2、3) b=copy.deepcopy (a) 打印(“=% s ' %) #一个=(1、2、3) 打印(" b=% s ' % b) # b=(1、2、3) b.append (4) 打印(“=% s ' %) #一个=(1、2、3) 打印(" b=% s ' % b) # b=(1、2、3、4)从代码执行情况来看,我们已经实现了深拷贝。这时我们再来看下两个变量的地址值:
<前> 打印(id (a)) # 4321416008 打印(id (b)) # 4321416200果然就不一样了。我们再通过一个图来看下深拷贝的原理:
从深拷贝的实现过程,我们知道复制模块,也使用了里面的deepcopy()方法。下面我们来介绍下复制模块中()的副本与deepcopy()方法。
首先介绍我们已经使用过的deepcopy()方法,官方文档介绍如下:

简单解释下文档中对这个方法的说明:
1。返回值是对这个对象的深拷贝
2。如果拷贝发生错误,会报copy.err异常
3。存在两个问题,第一是如果出递归对象,会递归的进行拷贝,第二正因为会递归拷贝,会导致出现拷贝过多的情况
4。关于两种拷贝方式的区别都是相对是引用对象
前两点很好理解,针对第三点,我们用代码进行解释:
<前> 进口复制=(1、2、3) b=(3、4、5) c=[a, b] #列表嵌套 d=copy.deepcopy (c) 打印(c=% s的% c) # c=[[1, 2, 3], [3、4、5]] 打印(d=% s的% d) # d=[[1, 2, 3], [3、4、5]] c.append (4) 打印(c=% s的% c) # c=[(1、2、3), (3、4、5), 4] 打印(d=% s的% d) # d=[[1, 2, 3], [3、4、5]] c [0] .append(4) #相当于a.append (4) 打印(c=% s的% c) # c=[(1、2、3、4), (3、4、5), 4] 打印(d=% s的% d) # d=[[1, 2, 3], [3、4、5]] # a.append (4) #打印(c=% s的% c) #一个=(1、2、3) #打印(d=% s的% d) # b=(1、2、3) 打印(id (c)) # 4314188040 打印(id (d)) # 4314187976 打印(id (c [0])) # 4314186568 打印(id (d [0])) # 4314187912 打印(id (a)) # 4314186568 打印(id (b)) # 4314186760



