
熊猫的qcut可以把一组数字按大小区间进行分区,比如
比如我要把这组数据分成两部分,一半大的,一半小的,如果是小的数,值就变成“少数”,大的数,值就变成“大量”:
qcut()方法第一个参数是数据,第二个参数定义区间的分割方法,比如这里把数字分成两半,那就是[0、0.5、1]如果要分成4份,就是[0,0.25,0.5,0.75,1),也可以不是均分,比如[0,0.1,0.2,0.3,1],这就就会按照1:1:1:7进行分布,比如:
当然,这里因为数据里有11个数,没法刚好按照1:1:1:7分,所以0和1,都被分到了‘first10%’这一类。
qcut()方法第二个参数是要替换的值,就是对应区间的值应该替换成什么值,顺序和区间保持一致就好了,注意有几个区间,就要给几个值,不能多也不能少。
qcut:传入参数,要将数据分成多少组,即组的个数,具体的组距是由代码计算
减少:传入参数,是分组依据。具体见示例
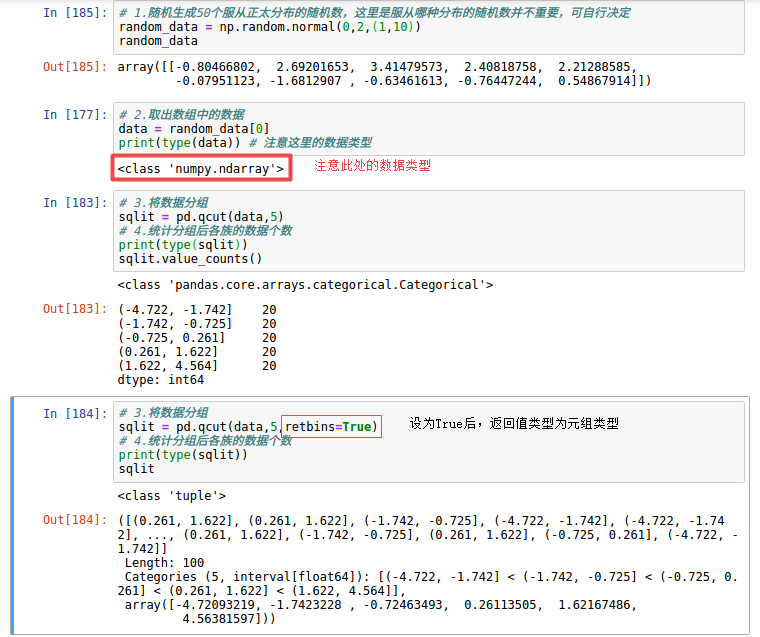
1, qcut方法,参考链接:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.qcut.html
1)。参数:<代码>熊猫。 <代码> qcut ( x , , 标签=, retbins=False , 精密=3 、复制=俺锛?/em>)
,祝辞祝辞的在x要进行分组的数据,数据类型为一维数组,或系列对象
,祝辞祝辞的在问组数,即要将数据分成几组,后边举例说明
祝辞祝辞祝辞标签可以理解为组标签,这里注意标签个数要和组数相等
祝辞祝辞祝辞retbins默认为假,当为假时,返回值是分类类型(具有value_counts()方法),为真正的是返回值是元组
2)。举例
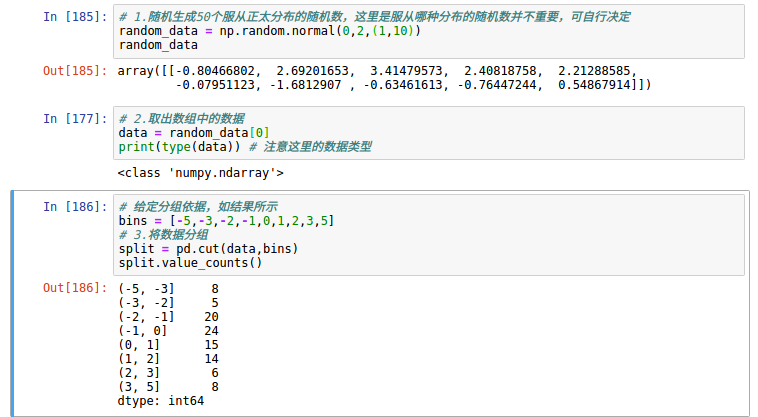
2.切方法,官网链接:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.cut.html
1)。参数:pandas.cut (x , 垃圾箱, =True , 标签=, retbins=False , 精密=3 、 include_lowest=False , 复制=俺锛?/em>)
2)。举例
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。




