
<强>一为什么使用复述,
在项目中使用复述,主要考虑两个角度:性能和并发。如果只是为了分布式锁这些其他功能,还有其他中间件Zookpeer等代替,并非一定要使用复述。
性能:
如下图所示,我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应。
特别是在秒杀系统,在同一时间,几乎所有人都在点,都在下单……执行的是同一操作,终止,和终止,和终止,向数据库查数据。
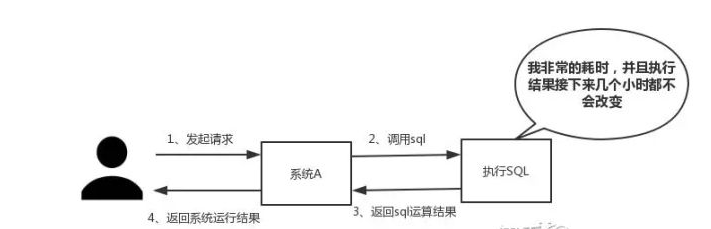
根据交互效果的不同,响应时间没有固定标准。在理想状态下,我们的页面跳转需要在瞬间解决,对于页内操作则需要在刹那间解决。
并发:
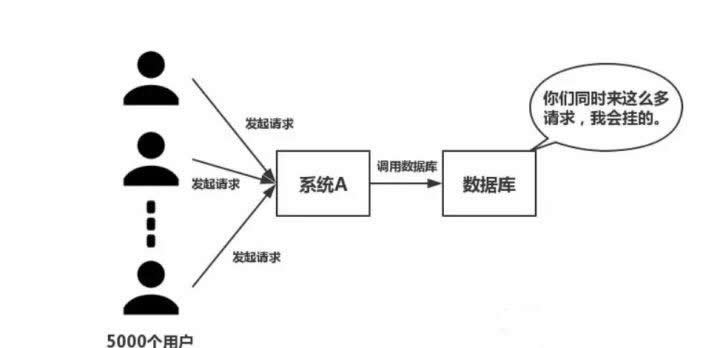
如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用复述,做一个缓冲操作,让请求先访问到复述,而不是直接访问数据库。
使用复述的常见问题缓存和数据库双写一致性问题缓存雪崩问题缓存击穿问题缓存的并发竞争问题二单线程的复述,为什么这么快
这个问题是对复述,内部机制的一个考察。很多人都不知道复述是单线程工作模型。
原因主要是以下三点:纯内存操作单线程操作,避免了频繁的上下文切换采用了非阻塞I/O多路复用机制
仔细说一说I/O多路复用机制,打一个比方:小名在一个城开了一家快餐店的店,负责同城快餐服务。小明因为资金限制,雇佣了一批配送员,然后小曲发现资金不够了,只够买一辆车送快递。
<强>经营方式一
客户每下一份订单,小明就让一个配送员盯着,然后让人开车去送。慢慢的小曲就发现了这种经营方式存在下述问题:
时间都花在了抢车上了,大部分配送员都处在闲置状态,抢到车才能去送。
随着下单的增多,配送员也越来越多,小明发现快递店里越来越挤,没办法雇佣新的配送员了。配送员之间的协调很花时间。综合上述缺点,小明痛定思痛,提出了经营方式二。经营方式二
小明只雇佣一个配送员。当客户下的单,小明按送达地点标注好,依次放在一个地方。最后,让配送员依次开着车去送,送好了就回来拿下一个,上述两种经营方式对比,很明显第二种效率更高。
在上述比喻中:每个配送员,rarr;每个线程每个订单,rarr;每个插座(I/O流)订单的送达地点,rarr;插座的不同状态客户送餐请求,rarr;来自客户端的请求明曲的经营方式,rarr;服务端运行的代码一辆车,rarr; CPU的核数于是有了如下结论:经营方式一就是传统的并发模型,每个I/O流(订单)都有一个新的线程(配送员)管理。经营方式二就是I/O多路复用。只有单个线程(一个配送员),通过跟踪每个I/O流的状态(每个配送员的送达地点),来管理多个I/O流。
下面类比到真实的复述,线程模型,如图所示:
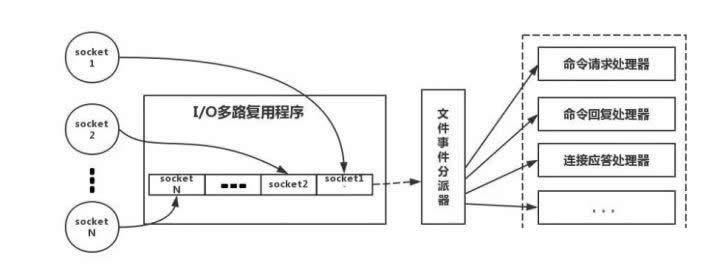
Redis-client在操作的时候,会产生具有不同事件类型的插座。在服务端,有一段I/O多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
<强>三复述的数据类型及使用场景
一个合格的程序员,这五种类型都会用的到。
<强>字符串
最常规的设置/获取操作,价值可以是字符串也可以是数字。一般做一些复杂的计数功能的缓存。
<强>哈希
存价值这里放的是结构化的对象,比较方便的就是操作其中的某个字段。我在做单点登录的时候,就是用这种数据结构存储用户信息,以CookieId作为关键,设置30分钟为缓存过期时间,能很好的模拟出类似会话的效果。
<强>列表
使用列表的数据结构,可以做简单的消息队列的功能。另外,可以利用lrange命令,做基于复述的分页功能,性能极佳,用户体验好。
<强>设置
因为集堆放的是一堆不重复值的集合。所以可以做全局去重的功能。我们的系统一般都是集群部署,使用JVM自带的设置比较麻烦。另外,就是利用交集,并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。




