df.groupby()之后按照特定顺序输出,方便后续作图,或者跟其他df对比作图。
# #构造pd.DataFrame
patient_id=[' 71835318256532 ',
“87791375711”,
“66979212649388”,
“46569922967175”,
“998612492555522”,
“982293214194”,
“89981833848”,
“17912315786975”,
“4683495482494”,
“1484143378533”,
“56866972273357”,
“7796319285658”,
“414462476158336”,
“449519578512573”,
“61826664459895”)
周=[“星期二”,
“星期二”,
“星期三”,
“星期一”,
“星期二”,
“星期一”,
“星期五”,
“星期二”,
“星期一”,
“星期五”,
“星期六”,
“星期四”,
“星期三”,
“星期四”,
“星期三”)
d={patient_id: patient_id,“星期”:周}
测试=pd.DataFrame (data=https://www.yisu.com/zixun/d)
# #聚类计数
test.groupby(周)[' patient_id '] .count ()
# #输出
周
周五2
周一3
周六1
周四2
周二4
周三3
名称:patient_id dtype: int64
# #按照特定顺序输出
印第安纳州=(周一,周二,周三,周四,周五,周六的)
test.groupby(周)[' patient_id '] .count()(印第安纳州)
# #输出
周
周一3
周二4
周三3
周四2
周五2
周六1
名称:patient_id dtype: int64
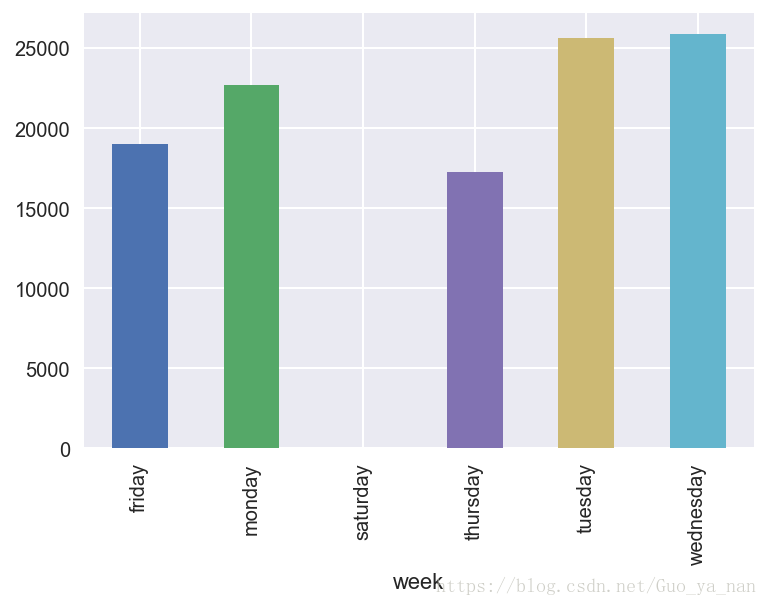
作图效果如下
test.groupby(周)[' patient_id '] .count () .plot(类型='酒吧');
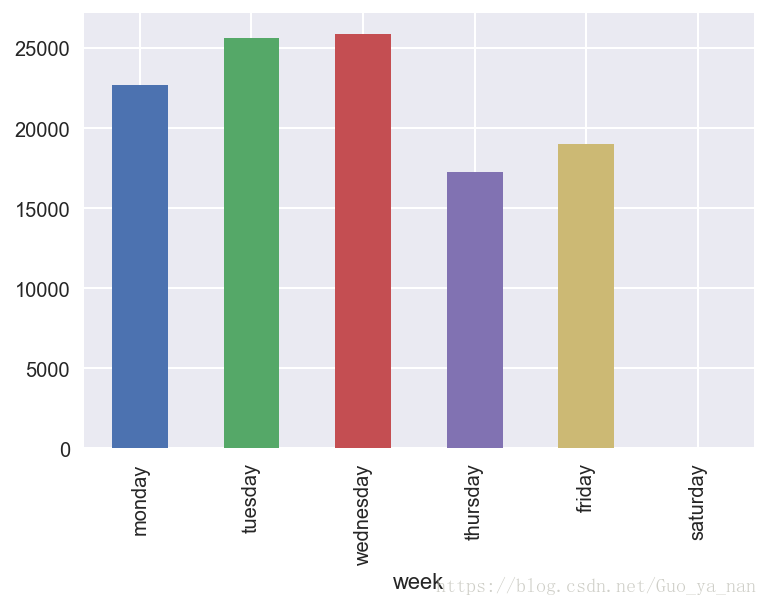
印第安纳州=(周一,周二,周三,周四,周五,周六的)
test.groupby(周)[' patient_id '] .count()(印第安纳州).plot(类型='酒吧');
以上所述是小编给大家介绍的熊猫按照特定顺序输出的实现代码,希望对大家有所帮助,如果大家有任何疑问请给我留的言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!





