<强>爬虫的起因
官方文档或手册虽然可以查阅,但是如果变成纸质版的岂不是更容易翻阅与记忆。如果简单的复制粘贴,不知道何时能够完成。于是便开始想着将Android的官方手册爬下来。
<强>全篇的实现思路
<李>分析网页
<李>学会使用BeautifulSoup库李
<李>爬取并导出
李
<强>参考资料:
*把廖雪峰的教程转换为PDF电子书
*请求文档
* Beautiful Soup文档
<>强配置
在Ubuntu下使用Pycharm运行成功
转PDF需要下载wkhtmltopdf
<强>具体过程
如下所示的一个网页,要做的是获取该网页的正文和标题,以及左边导航条的所有网址
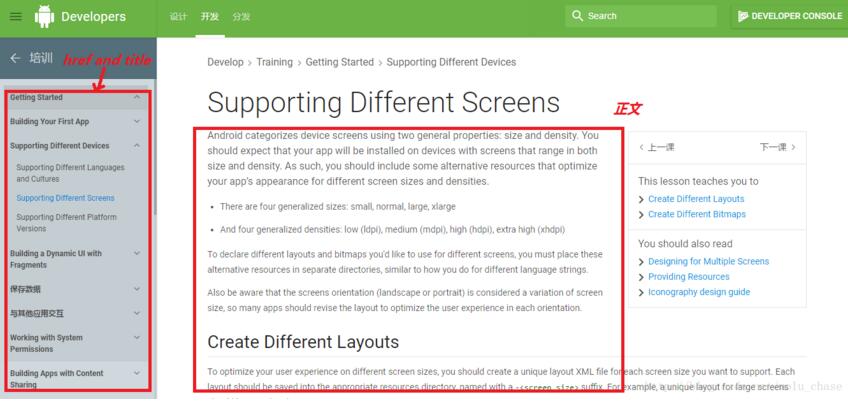
接下来的工作就是找到这些标签喽…
<>强关于请求的使用
详细参考文档,这里只是简单的使用请求获取html以及使用代理翻墙(网站无法直接访问,需要VPN)
代理={
“http”:“http://vpn的IP:端口”,
“https”:“https://vpn的IP:端口”,
}
响应=requests.get (url,代理=代理)
<强> Beautiful Soup的使用
参考资料里面有美丽的汤文档,将其看完后,可以知道就讲了两件事:一个是查找标签,一个是修改标签。
本文需要做的是:
1。获取标题和所有的网址,涉及到的是查找标签
#对标签进行判断,一个标签含有href而不含有描述,则返回现实
#而我希望获取的是含有href属性而不含有描述属性的& lt; a>标签,(且只有一个标签含有href)
def has_href_but_no_des(标签):
返回tag.has_attr (“href”),而不是tag.has_attr(描述)
#网页分析,获取网址和标题
def parse_url_to_html (url):
响应=requests.get (url,代理=代理)
汤=BeautifulSoup (response.content“html.parser”)
s=[] #获取所有的网址
title=[] #获取对应的标题
标签=soup.find (id=暗己健?#获取第一个id为“导航”的标签,这个里面包含了网址和标题
因为我在tag.find_all (has_href_but_no_des):
s.append(我(“href”))
title.append (i.text)
#获取的只是标签集,需要加html前缀
html=" & lt; html> & lt; head> & lt;元charset=皍tf - 8”祝辞& lt;/head> & lt; body>”
张开(“android_training_3.html”、“a”) f:
f.write (html)
对上面获取的网址分析,获取正文,并将图片取出存于本地;涉及到的是查找标签和修改属性
#网页操作,获取正文及图片
def get_htmls (url、标题):
因为我在范围(len (url)):
响应=requests.get (url(我),代理=代理)
汤=BeautifulSoup (response.content“html.parser”)
html=" & lt; div> & lt; h2>“+ str (i) +“。”+标题[我]+“& lt;/h2> & lt;/div>”
标签=soup.find (class_=癹d-descr”)
#为形象添加相对路径,并下载图片
img的tag.find_all (img):
我=请求。get (img (“src”),代理=代理)
文件名=os.path.split (img [“src”]) [1]
张开(“图像/?文件名,“世界银行”)f:
f.write (im.content)
img (“src”)=巴枷??文件名
html=html + str(标签)
张开(“android_training_3.html”、“a”) f:
f.write (html)
print (”(% s) (% s)下载结束”%(我[我]),标题)
html=" & lt;/body> & lt;/html>”
张开(“android_training_3.html”、“a”) f:
f.write (html)
2。转为PDF
这一步需要下载wkhtmltopdf,在Windows下执行程序一直出错. .Ubuntu下可以
def save_pdf (html):
”“”
把所有html文件转换成pdf文件
”“”
选择={
“页面大小”:“信”,
“编码”:“utf - 8”,
“自订标头”:(
(“接受编码”、“gzip”)
]
}
android_training_3 pdfkit.from_file (html。”pdf”,选项=选项)
最后的效果图