这篇文章将为大家详细讲解有关蜂巢函数有什么用,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
首先我们要知道蜂箱到底是做什么的。下面这几段文字很好的描述了蜂巢的特性:
1。蜂巢是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类sql语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
2。蜂巢是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储,查询和分析存储在Hadoop中的大规模数据的机制.Hive定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据,同时,这个语言也允许熟悉MapReduce开发者的开发自定义的mapper和减速器来处理内建的mapper和减速机无法完成的复杂的分析工作。
要理解蜂巢,必须先理解Hadoop MapReduce和,如果有不熟悉的童鞋,可以百度一下。
使用蜂巢的命令行接口,感觉很像操作关系数据库,但是蜂巢和关系数据库还是有很大的不同,下面我就比较下蜂巢与关系数据库的区别,具体如下:
1.蜂巢和关系数据库存储文件的系统不同,蜂巢使用的是Hadoop的HDFS (Hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
2.蜂巢使用的计算模型是MapReduce,而关系数据库则是自己设计的计算模型;
3。关系数据库都是为实时查询的业务进行设计的,而蜂窝则是为海量数据做数据挖掘设计的,实时性很差;实时性的区别导致蜂巢的应用场景和关系数据库有很大的不同,
4。蜂巢很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比数据库差很多。
以上都是从宏观的角度比较蜂巢和关系数据库的区别,蜂巢和关系数据库的异同还有很多,我在文章的后面会一一描述。
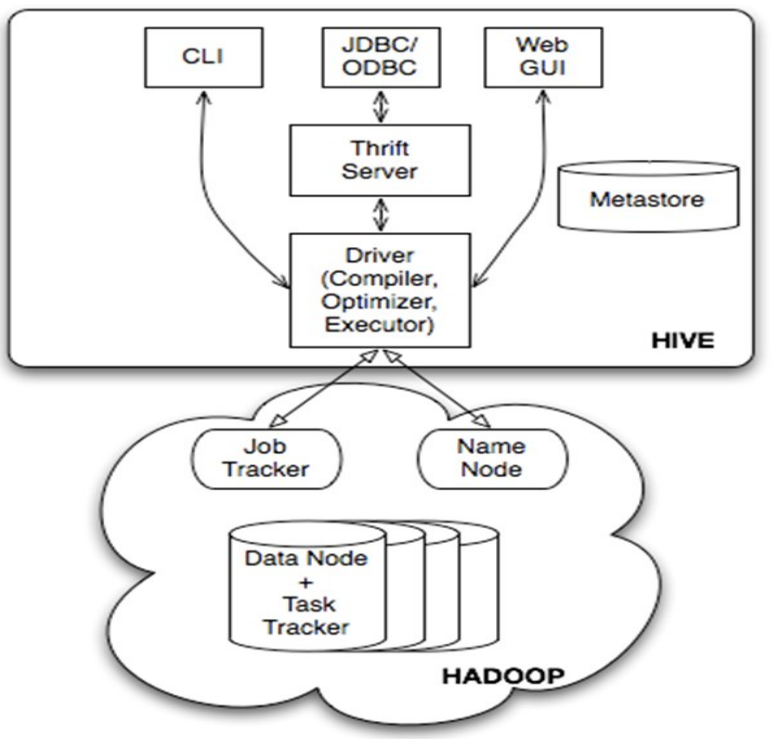
下面我来讲讲蜂巢的技术架构,大家先看下面的架构图:,