这期内容当中小编将会给大家带来有关Python爬虫中的Pyspider如何使用,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
1 简介
pyspider 是一个支持任务监控、项目管理、多种数据库,具有 WebUI 的爬虫框架,它采用 Python 语言编写,分布式架构。详细特性如下:
·拥有 Web 脚本编辑界面,任务监控器,项目管理器和结构查看器;
·数据库支持 MySQL、MongoDB、Redis、SQLite、Elasticsearch、PostgreSQL、SQLAlchemy;
·队列服务支持 RabbitMQ、Beanstalk、Redis、Kombu;
·支持抓取 JavaScript 的页面;
·组件可替换,支持单机、分布式部署,支持 Docker 部署;
·强大的调度控制,支持超时重爬及优先级设置;
·支持 Python2&3。
pyspider 主要分为 Scheduler(调度器)、 Fetcher(抓取器)、 Processer(处理器)三个部分,整个爬取过程受到 Monitor(监控器)的监控,抓取的结果被 Result Worker(结果处理器)处理。基本流程为:Scheduler 发起任务调度,Fetcher 抓取网页内容,Processer 解析网页内容,再将新生成的 Request 发给 Scheduler 进行调度,将生成的提取结果输出保存。
2 pyspider vs scrapy
·pyspider 拥有 WebUI,爬虫的编写、调试可在 WebUI 中进行;Scrapy 采用采用代码、命令行操作,实现可视化需对接 Portia。
·pyspider 支持使用 PhantomJS 对 JavaScript 渲染页面的采集 ;Scrapy 需对接 Scrapy-Splash 组件。
·pyspider 内置了 PyQuery(Python 爬虫(五):PyQuery 框架) 作为选择器;Scrapy 对接了 XPath、CSS 选择器、正则匹配。
·pyspider 扩展性弱;Scrapy 模块之间耦合度低,扩展性强,如:对接 Middleware、 Pipeline 等组件实现更强功能。
总的来说,pyspider 更加便捷,Scrapy 扩展性更强,如果要快速实现爬取优选 pyspider,如果爬取规模较大、反爬机制较强,优选 scrapy。
3 安装
3.1 方式一
pip install pyspider
这种方式比较简单,不过在 Windows 系统上可能会出现错误:Command "python setup.py egg_info"失败与错误…,我在自己的Windows系统上安装时就遇到了该问题,因此,选择了下面第二种方式进行了安装。
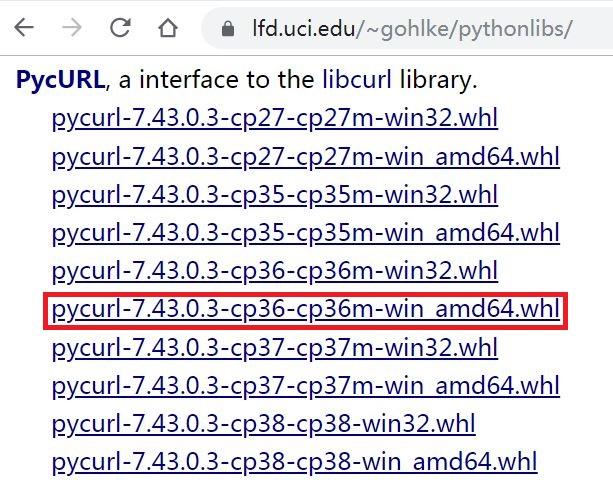
<强> 3.2方式二
使用车轮方式安装。步骤如下:
<强>· pip安装轮安装轮;
<强>·强打开网址https://www.lfd.uci.edu/~ gohlke/pythonlibs/,使用Ctrl + F搜索pycurl,根据自己安装的Python版本,选择合适的版本下载,比如:我用的Python3.6,就选择带有cp36标识的版本。如下图红框所示: