介绍
这篇文章将为大家详细讲解有Python爬关虫之Get和Post请求是什么意思,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
在说Get和Post请求之前,我们先来看一下url的编码和解码,我们在浏览器的链接里如果输入有中文的话,如:https://www.baidu.com/s?wd=贴吧,那么浏览器会自动为我们编码成:https://www.baidu.com/s?wd=% E8%B4%B4%E5 % 90% a7在Python2。x中我们需要使用urllib模块的urlencode方法,但我们在之前的文章已经说过之后的内容以Python3。x为主,所以我们就说一下Python3。x中的编码和解码。
在Python3。x中,我们需要引入urllib。解析模块,如下:
import urllib.parse
data=https://www.yisu.com/zixun/{“千瓦”:“贴吧”}
#通过urlencode()方法,将字典键值对按URL编码转换,从而能被web服务器接受。
data=urllib.parse.urlencode(数据)
打印(数据)#千瓦=% E8%B4%B4%E5 % 90% a7
#通过结束()方法,把URL编码字符串,转换回原先字符串。
data=urllib.parse.unquote(数据)
打印(数据)#千瓦=贴吧 <强>下面我们来看一下得到请求
得到请求一般用于我们向服务器获取数据,比如说,我们用百度搜索贴吧,结果如下:
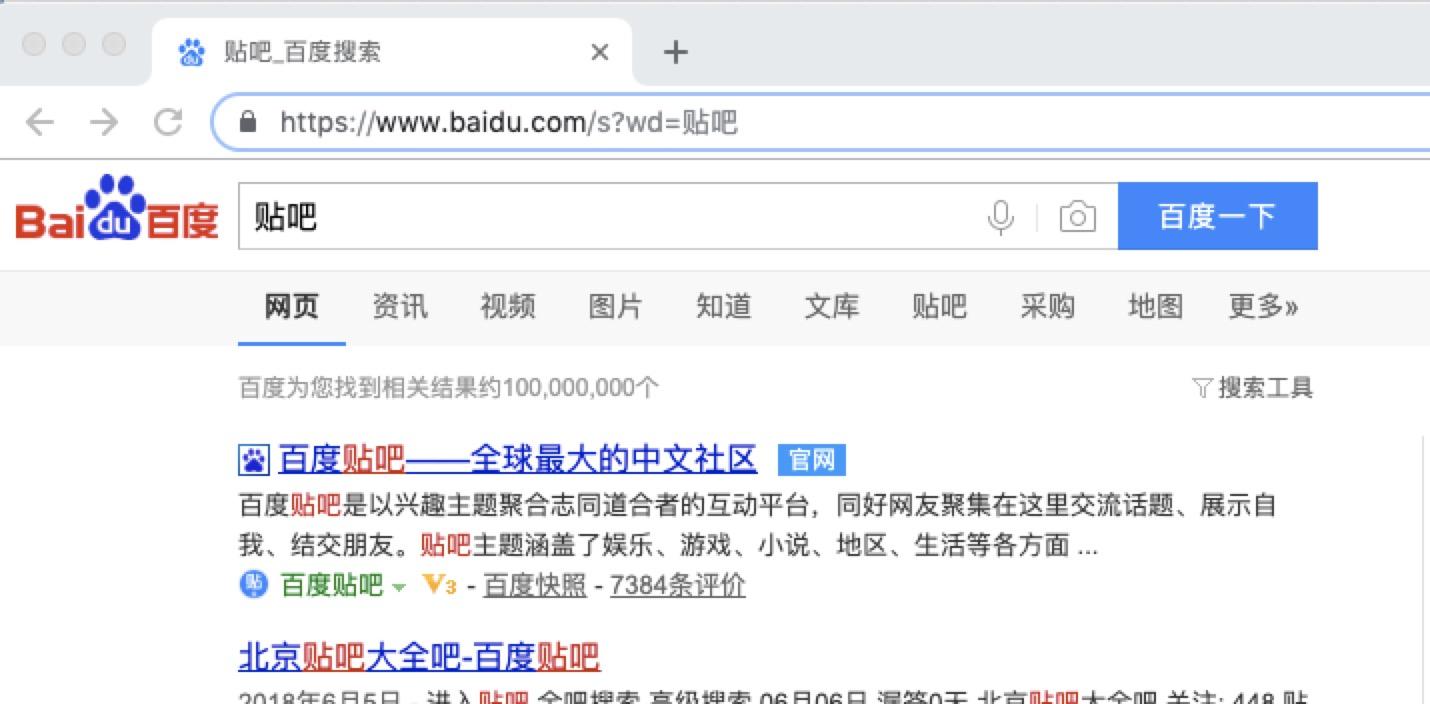
在其中我们可以看到在请求部分里,http://www.baidu.com/s?之后出现一个长长的字符串,其中就包含我们要查询的关键词贴吧,于是我们可以尝试用默认的得到方式来发送请求。
import urllib.request
import urllib.parse
ssl import
#,取消代理验证
ssl._create_default_https_context =ssl._create_unverified_context
#,url 地址
时间=url “http://www.baidu.com/s"
word =, {“wd":“贴吧“}
时间=word urllib.parse.urlencode(词),,#,转换成url编码格式(字符串)
+=url url “?“, +, word , #, url首个分隔符就是,?
#,用户代理
headers =, {“User-Agent":“Mozilla/5.0, (Macintosh;, Intel Mac OS X 10 _14_4), AppleWebKit/537.36, (KHTML, like 壁虎),
Chrome/73.0.3683.103 Safari/537.36“}
#,url 作为请求()方法的参数,构造并返回一个请求对象
时间=request urllib.request.Request (url,头=标题)
#,请求对象作为urlopen()方法的参数,发送给服务器并接收响应
时间=response urllib.request.urlopen(请求)
,
#,类文件对象支持,文件对象的操作方法,如阅读()方法读取文件全部内容,返回字符串
时间=html response.read () .decode (“utf-8")
#,打印字符串
打印(html) 我们在请求页面的时候将我们要传的值直接通过转码拼接在url地址后面,然后就可以获取到我们想要的内容了,最终结果如下:
通过开发者工具看页面的html和我们得到的结果是完全一致的。
接下来我们看一下帖子请求,先来看一个帖子请求接口:https://movie.douban.com/j/chart/top_list?type=11& interval_id=100:90&=0开始,限制=10,该接口为豆瓣的一个电影列表接口,为文章请求,url问号后面的为请求参数,结果如下:
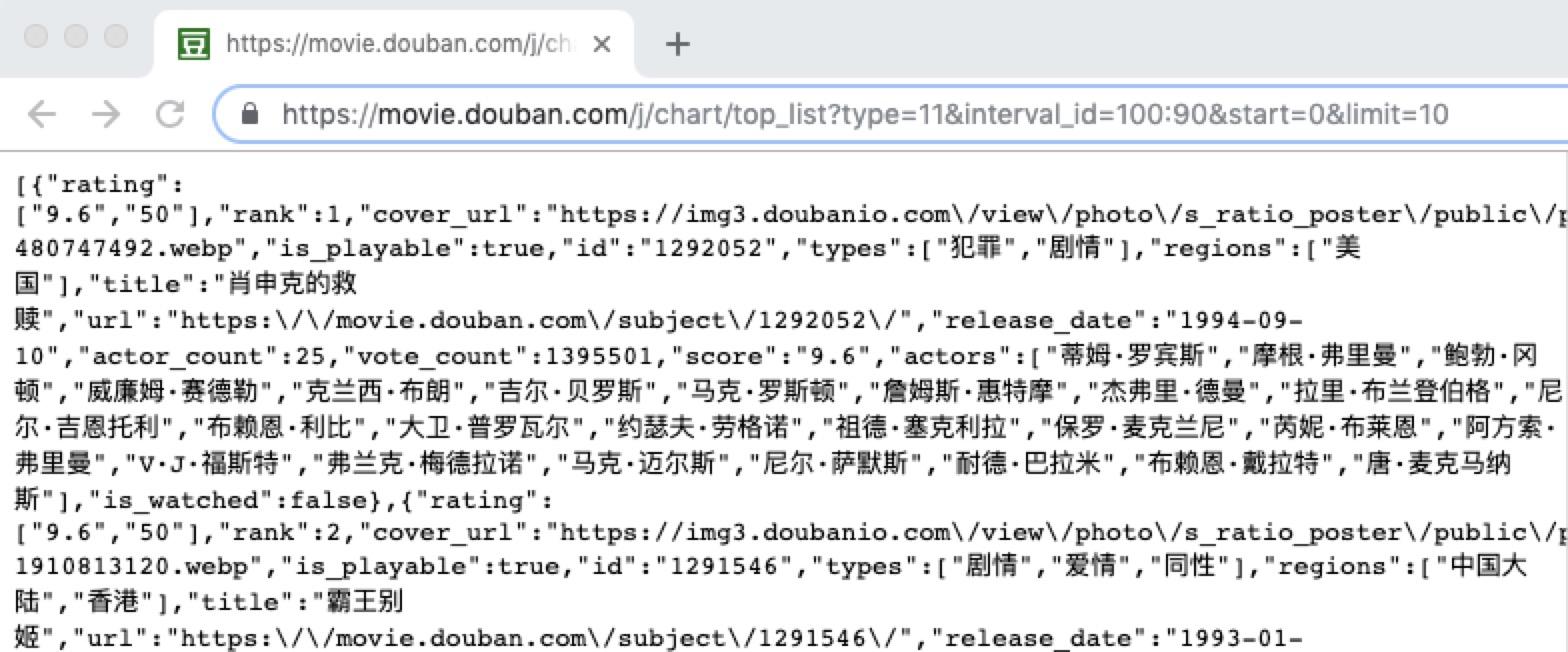
如果我们要使用urllib的帖子请求,则要在请求第二个参数加入我们想要的参数,如下:
import urllib.request
import urllib.parse
ssl import
#,取消代理验证
ssl._create_default_https_context =ssl._create_unverified_context
#,用户代理
headers =, {“User-Agent":“Mozilla/5.0, (Macintosh;, Intel Mac OS X 10 _14_4), AppleWebKit/537.36, (KHTML, like 壁虎),
Chrome/73.0.3683.103 Safari/537.36“}
#,post 请求参数
data =, {
,,,“type":,“11”,
,,,“interval_id":,“100:90"
,,,“时:,“0”,
,,,“limit":,“10”;
}
时间=data urllib.parse.urlencode(数据).encode (“utf-8")
#,url 作为请求()方法的参数,构造并返回一个请求对象
时间=request urllib.request.Request (“https://movie.douban.com/j/chart/top_list?",, data=https://www.yisu.com/zixun/data,头=标题)
#请求对象作为urlopen()方法的参数,发送给服务器并接收响应
响应=urllib.request.urlopen(请求)
#类文件对象支持文件对象的操作方法,如阅读()方法读取文件全部内容,返回字符串
html=response.read () .decode (“utf - 8”)
#打印字符串
打印(html)





