
最近学完Python,写了几个爬虫练练手,网上的教程有很多,但是有的已经不能爬了,主要是网站经常改,可是爬虫还是有通用的思路的,即下载数据,解析数据,保存数据。下面一一来讲。
首先打开要爬的网站,分析URL,每打开一个网页看URL有什么变化,有可能带上上个网页的某个数据,例如xxID之类,那么我们就需要在上一个页面分析HTML,找到对应的数据。如果网页源码找不到,可能是ajax异步加载,去xhr里去找。
, 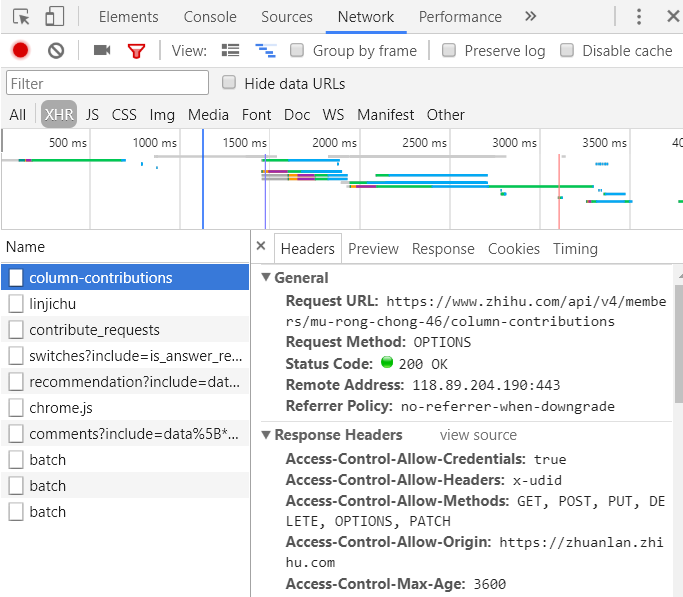 自我。user_agent=' Mozilla/4.0 (compatible;MSIE 5.5;Windows NT) '
#初始化标头
自我。头={“用户代理”:self.user_agent}
自我。user_agent=' Mozilla/4.0 (compatible;MSIE 5.5;Windows NT) '
#初始化标头
自我。头={“用户代理”:self.user_agent}
如果不行,在Chrome上按F12分析请求头,请求体,看需不需要添加别的信息,例如有的网址添加了推荐人:记住当前网页的来源,那么我们在请求的时候就可以带上。按Ctrl + Shift + C,可以定位元素在HTML上的位置
有一些网页是动态网页,我们得到网页的时候,数据还没请求到呢,当然什么都提取不出来,用Python解决这个问题只有两种途径:直接从JavaScript代码里采集内容,或者用Python的第三方库运行JavaScript,直接采集你在浏览器里看到的页面。
1。找请求,看返回的内容,网页的内容可能就在这里。然后可以复制请求,复杂的网址中,有些乱七八糟的可以删除,有意义的部分保留。切记删除一小部分后先尝试能不能打开网页,如果成功再删减,直到不能删减。
2。硒:是一个强大的网络数据采集工具(但是速度慢),其最初是为网站自动化测试而开发的。近几年,它还被广泛用于获取精确的网站快照,因为它们可以直接运行在浏览器上.Selenium库是一个在WebDriver上调用的API。
WebDriver有点儿像可以加载网站的浏览器,但是它也可以像BeautifulSoup对象一样用来查找页面元素,与页面上的元素进行交互(发送文本,点击等),以及执行其他动作来运行网络爬虫。
PhantomJS:是一个“无头”(headless)浏览器。它会把网站加载到内存并执行页面上的JavaScript,但是它不会向用户展示网页的图形界面。把硒和PhantomJS结合在一起,就可以运行一个非常强大的网络爬虫了,可以处理cookie, JavaScript,头,以及任何你需要做的事情。
请求相比其他俩个的话,支持HTTP连接保持和连接池,支持使用饼干保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的URL和帖子数据自动编码,而且api相对来说也简单,但是请求直接使用不能异步调用,速度慢。
<强> urllib2以我爬取淘宝的妹子例子来说明:,
<强> 
解析数据也有很多方式,我只看了beautifulsoup和正则,这个例子是用正则来解析的




