
对于现在流行的深度学习,保持学习精神是必要的——程序员尤其是架构师永远都要对核心技术和关键算法保持关注和敏感,必要时要动手写一写掌握下来,先不用关心什么时候用到——用不用是政治问题,会不会写是技术问题,就像军人不关心打不打的问题,而要关心如何打赢的问题。
对程序员来说,机器学习是有一定门槛的(这个门槛也是其核心竞争力),相信很多人在学习机器学习时都会为满是数学公式的英文论文而头疼,甚至可能知难而退,但实际上机器学习算法落地程序并不难写,下面是70行代码实现的反向多层(BP)神经网络算法,也就是深度学习。其实不光是神经网络,逻辑回归,决策树C45/ID3,随机森林,贝叶斯,协同过滤,图计算,Kmeans, PageRank等大部分机器学习算法都能在100行单机程序内实现(以后考虑分享出来)。
机器学习的真正难度在于它为什么要这么计算,它背后的数学原理是什么,怎么推导得来的公式,网上大部分的资料都在介绍这部分理论知识,却很少告诉你该算法的计算过程和程序落地是怎么样的,对于程序员来说,你需要做的仅是工程化应用,而不需要证明出一项新的数学计算方法。实际大部分机器学习工程师都是利用别人写好的开源包或者工具软件,输入数据和调整计算系数来训练结果,甚至很少自己实现算法过程。但是掌握每个算法的计算过程仍然非常重要,这样你才能理解该算法让数据产生了什么样的变化,理解算法的目的是为了达到什么样的效果。
本文重点探讨反向神经网络的单机实现,关于神经网络的多机并行化,Fourinone提供非常灵活完善的并行计算框架,我们只需要理解透单机程序实现,就能构思和设计出分布式并行化方案,如果不理解算法计算过程,一切思路将无法展开。另外,还有卷积神经网络,主要是一种降维思想,用于图像处理,不在本文讨论范围。
首先,要明确,神经网络做的是预测任务,相信你记得高中学过的最小二乘法,我们可以以此做一个不严谨但比较直观的类比:
首先,我们要得到一个数据集和数据集的标记(最小二乘法中,我们也得到了一组组x, y的值)
算法根据这个数据集和对应的标记,拟合一个能够表达这个数据集的函数参数(也就是最小二乘法中计算a, b的公式,神经网络中不过是这个公式没法直接得到)
我们以此得到了拟合的函数(也就是最小二乘法中的拟合直线y ^=ax + b)
接下来,带入新的数据之后,就可以生成对应的预测值y ^(在最小二乘法中,就是带入y ^=ax + b得到我们预测的y ^,神经网络算法也是的,只不过求得的函数比最小二乘法复杂得多)。
神经网络结构如下图所示,最左边的是输入层,最右边的是输出层,中间是多个隐含层,隐含层和输出层的每个神经节点,都是由上一层节点乘以其权重累加得到,标上“+ 1”的圆圈为截距项b,对输入层外每个节点:Y=w0 * x0 + w1 * x1 +…+ wn * xn + b,由此我们可以知道神经网络相当于一个多层逻辑回归的结构。
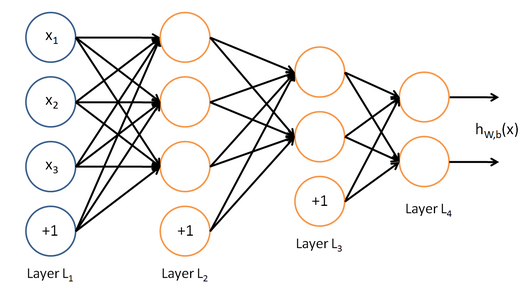
算法计算过程:输入层开始,从左往右计算,逐层往前直到输出层产生结果。如果结果值和目标值有差距,再从右往左算,逐层向后计算每个节点的误差,并且调整每个节点的所有权重,反向到达输入层后,又重新向前计算,重复迭代以上步骤,直到所有权重参数收敛到一个合理值。由于计算机程序求解方程参数和数学求法不一样,一般是先随机选取参数,然后不断调整参数减少误差直到逼近正确值,所以大部分的机器学习都是在不断迭代训练,下面我们从程序上详细看看该过程实现就清楚了。
神经网络的算法程序实现分为初始化,向前计算结果,反向修改权重三个过程。
<强> 1。初始化过程
由于是n层神经网络,我们用二维数组层记录节点值,第一维为层数,第二维为该层节点位置,数组的值为节点值;同样,节点误差值layerErr也是相似方式记录。用三维数组layer_weight记录各节点权重,第一维为层数,第二维为该层节点位置,第三维为下层节点位置,数组的值为某节点到达下层某节点的权重值,初始值为0 - 1之间的随机数。为了优化收敛速度,这里采用动量法权值调整,需要记录上一次权值调整量,用三维数组layer_weight_delta来记录,截距项处理:程序里将截距的值设置为1,这样只需要计算它的权重就可以了,




