
本文实例讲述了Python熊猫RFM模型应用。分享给大家供大家参考,具体如下:
什么是RFM模型
根据美国数据库营销研究所阿瑟·休斯的研究,客户数据库中有3个神奇的要素,这3个要素构成了数据分析最好的指标:
-
<李> <>强最近一次消费(近因):客户最近一次交易时间的间隔r值越大,表示客户交易距今越久,反之则越近,李
<李> <>强消费频率(频率):客户在最近一段时间内交易的次数.F值越大,表示客户交易越频繁,反之则不够活跃,李
<李> <>强消费金额(货币):客户在最近一段时间内交易的金额。m值越大,表示客户价值越高,反之则越低。
RFM实践应用
1,前提假设验证
RFM模型的应用是有前提假设的,即R F M值越大价值越大,客户未来的为企业带来的价值越大。这个前提假
设其实已经经过大量的研究和实证、假设是成立的。不过为了更加严谨,确保RFM模型对于特殊案例是有效的,
本文还进行了前提假设验证:
ps:频率、货币均为近6个月内的数据,即1 - 6月数据;
利用相关性检验,验证假设:
-
<李>最近购买产品的用户更容易产生下一次消费行为李
<李>消费频次高的用户,用户满意度高,忠诚度高,更容易产生下一次消费行为李
<李>消费金额高的用户更容易带来高消费行为李
2, RFM分级
简单的做法,RFM三个指标以均值来划分,高于均值的为高价值,低于均值的为低价值,如此可以将客户划分为八大类:
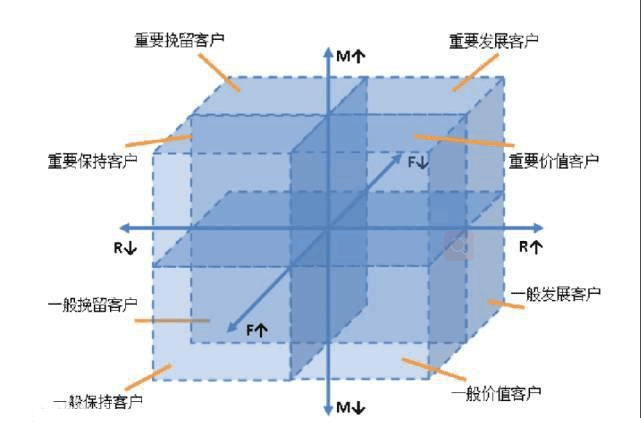
本文采取的方法是将三个指标进行标准化,然后按照分为数划分为5个等级,数值越大代表价值越高,当然最终划分的规则还是要结合业务来定。划分为5个等级后,客户可以细分为125种。
3,客户分类
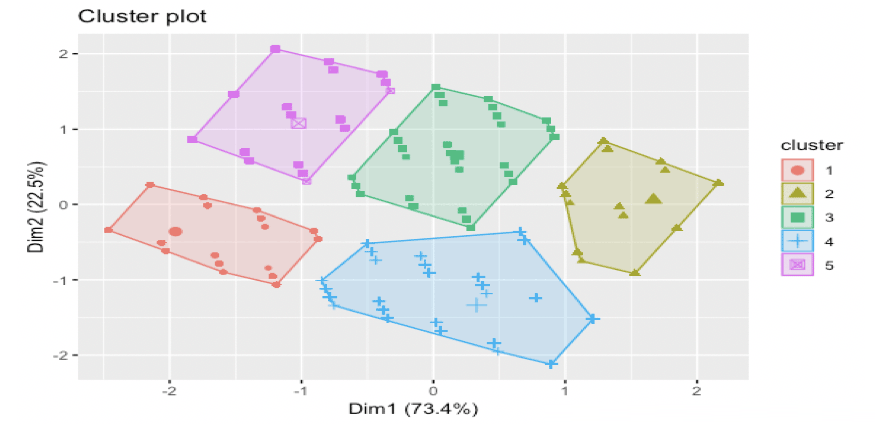
本文采用k - means聚类进行分类,聚类结果结合业务划分为4大类:
-
<李> Cluster1:价值用户R F M三项指标均较高,李
<李> Cluster2, 3:用户贡献值最低,且用户近度(小于2)和频度较低,为无价值客户;李
<李> Cluster4:发展用户,用户频度和值度较低,但用户近度较高,可做起来营销;李
<李> Cluster5:挽留客户,用户近度较低,但频度和值度较高,需采用挽留手段李
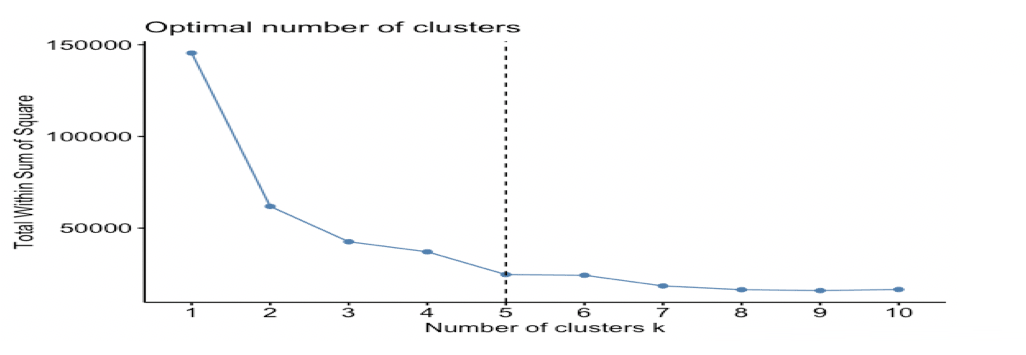
k值选择:
聚类结果:
4, RFM打分
步骤3,我们将客户划分为四大类,其实如果一类客户中还有大量的客户,此时为了精细化营销,可以根据RFM进行加权打分,给出一个综合价值的分。这里,运用AHP层次分析法确定RFM各指标权重:




