<强>为什么要实现服务端渲染(SSR)
总结下来有以下几点:
-
<李> SEO,让搜索引擎更容易读取页面内容李
<李>首屏渲染速度更快(重点),无需等待js文件下载执行的过程李
<李>代码同构,服务端和客户端可以共享某些代码李
今天我们将构建一个使用终极版的简单的反应应用程序,实现服务端渲染(SSR)。该示例包括异步数据抓取,这使得任务变得更有趣。
如果您想使用本文中讨论的代码,请查看GitHub: answer518/react-redux-ssr
在开始编写应用之前,需要我们先把环境编译/打包环境配置好,因为我们采用的是es6语法编写代码。我们需要将代码编译成es5代码在浏览器或节点环境中执行。
我们将用babelify转换来使用browserify和watchify来打包我们的客户端代码。对于我们的服务器端代码,我们将直接使用babel-cli。
代码结构如下:
我们在package.json里面加入以下两个命令脚本:
并发库帮助并行运行多个进程,这正是我们在监控更改时需要的。
最后一个有用的命令,用于运行我们的http服务器:
不使用<代码>节点。/构建/服务器/服务器。js代码而使用<代码> Nodemon>
假设服务端返回以下的数据格式:
我们通过一个组件将数据渲染出来。在这个组件的componentWillMount生命周期方法中,我们将触发数据获取,一旦请求成功,我们将发送一个类型为user_fetch的操作。该操作将由一个减速器处理,我们将在回来的存储中获得更新。状态的改变将触发我们的组件重新呈现指定的数据。
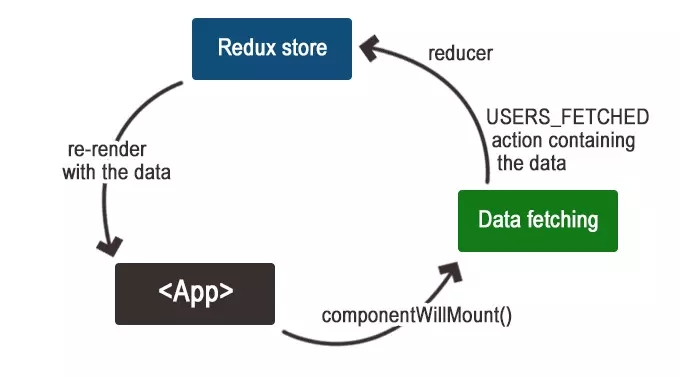
减速器处理过程如下:
为了能派发行动请求去改变应用状态,我们需要编写行动创造者:
回来的实现的最关键一步就是创建店:
为什么直接返回的是工厂函数而不是createStore(减速器)& # 63;这是因为当我们在服务器端渲染时,我们需要一个全新商店的实例来处理每个请求。
在这里需要提的一个重点是,一旦我们想实现服务端渲染,那我们就需要改变之前的纯客户端编程模式。
服务器端渲染,也叫代码同构,也就是同一份代码既能在客户端渲染,又能在服务端渲染。