项目描述:
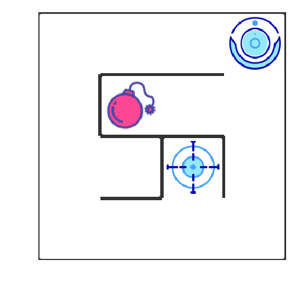
在该项目中,你将使用强化学习算法,实现一个自动走迷宫机器人。
如上图所示,智能机器人显示在右上角。在我们的迷宫中,有陷阱(红色×××)及终点(蓝色的目标点)两种情景。机器人要尽量避开陷阱,尽快到达目的地。
小车可执行的动作包括:向上走<代码> u> r> d> 。
执行不同的动作后,根据不同的情况会获得不同的奖励,具体而言,有以下几种情况。
-
<李>撞到墙壁:-10李
<李>走到终点:50
<李>走到陷阱:-30李
<李>其余情况:-0.1
我们需要通过修改<代码>机器人。py>
<强> 1.1强化学习总览
强化学习作为机器学习算法的一种,其模式也是让智能体在“训练”中学到“经验”,以实现给定的任务。但不同于监督学习与非监督学习,在强化学习的框架中,我们更侧重通过智能体与环境的交互来学习。通常在监督学习和非监督学习任务中,智能体往往需要通过给定的训练集,辅之以既定的训练目标(如最小化损失函数),通过给定的学习算法来实现这一目标。然而在强化学习中,智能体则是通过其与环境交互得到的奖励进行学习。这个环境可以是虚拟的(如虚拟的迷宫),也可以是真实的(自动驾驶汽车在真实道路上收集数据)。
在强化学习中有五个核心组成部分,它们分别是:环境(环境)、智能体(代理)状态(状态),动作(行动)和奖励(奖励)。在某一时间节点t:
智能体在从环境中感知其所处的状态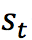
智能体根据某些准则选择动作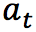
环境根据智能体选择的动作,向智能体反馈奖励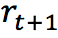
通过合理的学习算法,智能体将在这样的问题设置下,成功学到一个在状态
<强> 1.2计算Q值
在我们的项目中,我们要实现基于q学习的强化学习算法.Q-Learning是一个值迭代(值迭代)算法。与策略迭代(政策迭代)算法不同,值迭代算法会计算每个”状态”或是”状态,动作”的值(值)或是效用(效用),然后在执行动作的时候,会设法最大化这个值。因此,对每个状态值的准确估计,是我们值迭代算法的核心。通常我们会考虑最大化动作的长期奖励,即不仅考虑当前动作带来的奖励,还会考虑动作长远的奖励。
在Q学习算法中,我们把这个长期奖励记为Q值,我们会考虑每个”状态,动作”的Q值,具体而言,它的计算公式为:
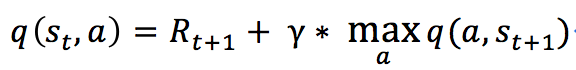
也就是对于当前的“状态,动作“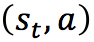 用q学习算法实现自动走迷宫机器人的方法示例
用q学习算法实现自动走迷宫机器人的方法示例