最近弄了一个用户发表评论的功能,用户上传了评论,再文章下可以看到自己的评论,但作为社会主义接班人,践行社会主义核心价值观,所以给评论敏感词过滤的功能不可少,在网上找了资料,发现已经有非常成熟的解决方案。常用的方案用这么两种
1。全文搜索,逐个匹配。这种听起来就不够高大上,在数据量大的情况下,会有效率问题,文末有比较
2。DFA算法——确定有限状态自动机附上百科链接确定有限状态自动机
<强> DFA算法介绍
DFA是一种计算模型,数据源是一个有限个集合,通过当前状态和事件来确定下一个状态,即状态+事件=下一状态,由此逐步构建一个有向图,其中的节点就是状态,所以在DFA算法中只有查找和判断,没有复杂的计算,从而提高算法效率
参考文章Java实现敏感词过滤
<>强实现逻辑
<>强构造数据结构
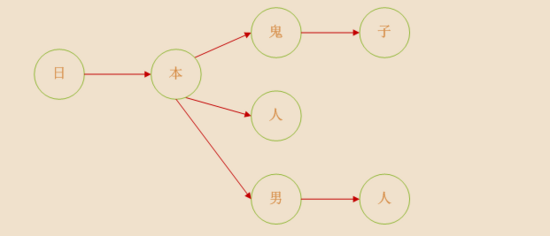
将敏感词转换成树结构,举例敏感词有着这么几个[的日本鬼子”,“日本人”,“日本男人”),那么数据结构如下(图片引用参考文章)
 /* *
* @description
*构造敏感词地图
* @private
* @returns
*/私人makeSensitiveMap (sensitiveWordList) {//构造根节点
const结果=新地图();
(const sensitiveWordList的话){
让地图=结果;
(让我=0;我& lt;word.length;我+ +){//依次获取字
const char=word.charAt(我);//判断是否存在
如果(map.get (char)) {//获取下一层节点
地图=map.get (char);
其他}{//将当前节点设置为非结尾节点
如果(map.get(持久之人)===true) {
地图。集(上鞋楦,假);
}
常数项=新地图();//新增节点默认为结尾节点
项。集(持久之人,真正的);
地图。集(char、项);
地图=map.get (char);
}
}
}
返回结果;
}
/* *
* @description
*构造敏感词地图
* @private
* @returns
*/私人makeSensitiveMap (sensitiveWordList) {//构造根节点
const结果=新地图();
(const sensitiveWordList的话){
让地图=结果;
(让我=0;我& lt;word.length;我+ +){//依次获取字
const char=word.charAt(我);//判断是否存在
如果(map.get (char)) {//获取下一层节点
地图=map.get (char);
其他}{//将当前节点设置为非结尾节点
如果(map.get(持久之人)===true) {
地图。集(上鞋楦,假);
}
常数项=新地图();//新增节点默认为结尾节点
项。集(持久之人,真正的);
地图。集(char、项);
地图=map.get (char);
}
}
}
返回结果;
}
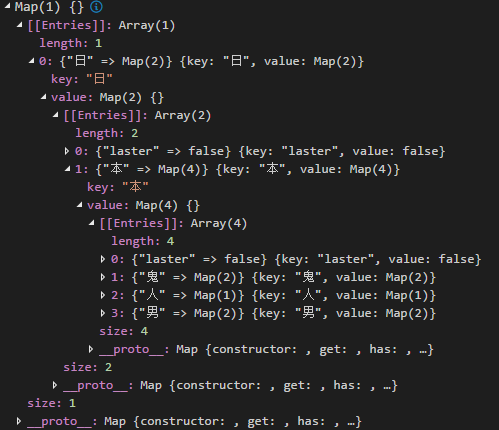
最终地图结构如下
 /* *
* @description
*检查敏感词是否存在
* @private
* @param{任何}txt
* @param{一}指数
* @returns
*/私人checkSensitiveWord (sensitiveMap、txt、索引){
让currentMap=sensitiveMap;
让国旗=false;
让wordNum=0;//记录过滤
让sensitiveWord=";//记录过滤出来的敏感词
(让我=指数;我& lt;txt.length;我+ +){
const词=txt.charAt(我);
currentMap=currentMap.get(词);
如果(currentMap) {
wordNum + +;
sensitiveWord +=单词;
如果(currentMap.get(持久之人)===true) {//表示已到词的结尾
国旗=true;
打破;
}
其他}{
打破;
}
}//两字成词
如果(wordNum & lt;2){
国旗=false;
}
返回{国旗,sensitiveWord};
}/* *
* @description
*判断文本中是否存在敏感词
* @param{任何}txt
* @returns
*/sensitiveMap公共filterSensitiveWord (txt) {
让matchResult={国旗:假的,sensitiveWord: "};//过滤掉除了中文,英文,数字之外的
const txtTrim=三种。替换(/[^ \ u4e00 - \ u9fa5 \ u0030 \ u0039 \ u0061 - \ u007a \ u0041 \ u005a] +/g,”);
(让我=0;我& lt;txtTrim.length;我+ +){
matchResult=checkSensitiveWord (sensitiveMap txtTrim,我);
如果(matchResult.flag) {
console.log (sensitiveWord: $ {matchResult.sensitiveWord});
打破;
}
}
返回matchResult;
}
/* *
* @description
*检查敏感词是否存在
* @private
* @param{任何}txt
* @param{一}指数
* @returns
*/私人checkSensitiveWord (sensitiveMap、txt、索引){
让currentMap=sensitiveMap;
让国旗=false;
让wordNum=0;//记录过滤
让sensitiveWord=";//记录过滤出来的敏感词
(让我=指数;我& lt;txt.length;我+ +){
const词=txt.charAt(我);
currentMap=currentMap.get(词);
如果(currentMap) {
wordNum + +;
sensitiveWord +=单词;
如果(currentMap.get(持久之人)===true) {//表示已到词的结尾
国旗=true;
打破;
}
其他}{
打破;
}
}//两字成词
如果(wordNum & lt;2){
国旗=false;
}
返回{国旗,sensitiveWord};
}/* *
* @description
*判断文本中是否存在敏感词
* @param{任何}txt
* @returns
*/sensitiveMap公共filterSensitiveWord (txt) {
让matchResult={国旗:假的,sensitiveWord: "};//过滤掉除了中文,英文,数字之外的
const txtTrim=三种。替换(/[^ \ u4e00 - \ u9fa5 \ u0030 \ u0039 \ u0061 - \ u007a \ u0041 \ u005a] +/g,”);
(让我=0;我& lt;txtTrim.length;我+ +){
matchResult=checkSensitiveWord (sensitiveMap txtTrim,我);
如果(matchResult.flag) {
console.log (sensitiveWord: $ {matchResult.sensitiveWord});
打破;
}
}
返回matchResult;
}