
要想分析MySQL查询语句中的相关信息,如是全表查询还是部分查询,就要用到解释。
<>强索引的优点
-
<李>大大减少了服务器需要扫描的数据量
<李>可以帮助服务器避免排序或减少使用临时表排序李
<李>索引可以随机I/O变为顺序I/O
李
<>强索引的缺点
-
<李>需要占用磁盘空间,因此冗余低效的索引将占用大量的磁盘空间李
<李>降低DML性能,对于数据的任意增删改都需要调整对应的索引,甚至出现索引分裂李
<李>索引会产生相应的碎片,产生维护开销李
用法:解释+查询语句。
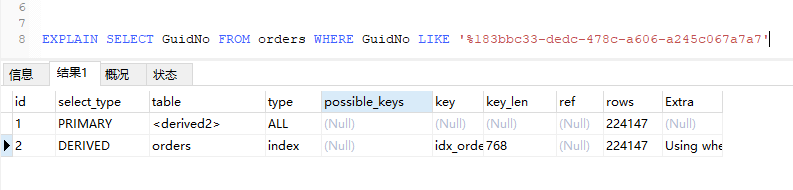
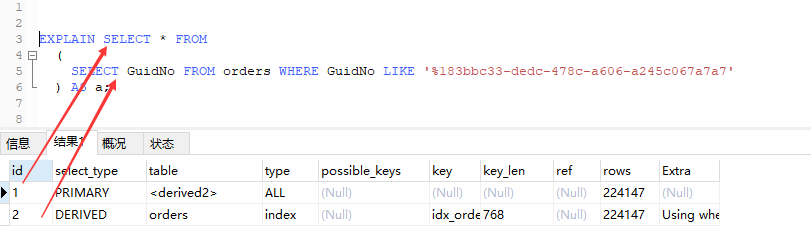
id:查询语句的序列号,上面图片中只有一个选择语句,所以只会显示一个序列号。如果有嵌套查询,如下
select_type:表示查询类型,有以下几种
简单:简单的选择(没有使用联盟或子查询)
主:最外层的选择。
联盟:第二层,在选择之后使用了联盟。
依赖联盟:联盟语句中的第二个选择,依赖于外部子查询
子查询:子查询中的第一个选择
相关子查询:子查询中的第一个查询依赖于外部的子查询
派生:派生表选择(从子句中的子查询)
表:查询的表,结果集
类型:全称为“加入类型”,意为连接类型。通俗的讲就是mysql查找引擎找到满足SQL条件的数据的方式,其值为:
-
<李>系统:系统表,表中只有一行数据李
<李> const:读常量,最多只会有一条记录匹配,由于是常量,实际上只须要读一次。
<李> eq_ref:最多只会有一条匹配结果,一般是通过主键或唯一键索引来访问。
<李>裁判:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取李
<李>全文:进行全文索引检索。
<李> ref_or_null:与裁判的唯一区别就是在使用索引引用的查询之外再增加一个空值的查询。
<李> index_merge:查询中同时使用两个(或更多)索引,然后对索引结果进行合并,再读取表数据。
<李> unique_subquery:子查询中的返回结果字段组合是主键或者唯一约束。
<李> index_subquery:子查询中的返回结果字段组合是一个索引(或索引组合),但不是一个主键或唯一索引。
<李>响了:索引范围扫描。
<李>指数:全索引扫描。
<李>:全表扫描。
性能从上到下依次降低。
possible_keys:可能用到的索引
关键:使用的索引
裁判:裁判列显示使用哪个列或常数与关键一起从表中选择行。
行:显示MySQL认为它执行查询时必须检查的行数。多行之间的数据相乘可以估算要处理的行数。
额外:额外的信息
-
<李>截然不同:MySQL发现第1个匹配行后,停止为当前的行组合搜索更多的行。
<李>不存在:MySQL能够对查询进行左加入优化,发现1个匹配离开加入标准的行后,不再为前面的的行组合在该表内检查更多的行。
<李>范围检查每条记录(指数映射:#):MySQL没有发现好的可以使用的索引,但发现如果来自前面的表的列值已知,可能部分索引可以使用。
<李>使用filesort: MySQL需要额外的一次传递,以找出如何按排序顺序检索行。
<李>使用指数:从只使用索引树中的信息而不需要进一步搜索读取实际的行来检索表中的列信息。
<李>使用临时:为了解决查询,MySQL需要创建一个临时表来容纳结果。
<李>使用地点:在子句用于限制哪一个行匹配下一个表或发送到客户。
<李>使用sort_union(…),使用联盟(…),使用相交(…):这些函数说明如何为index_merge联接类型合并索引扫描。
<李>使用指数GROUP BY:类似于访问表的使用索引方式,使用指数GROUP BY表示MySQL发现了一个索引,可以用来查询集团或不同的查询的所有列,而不要额外搜索硬盘访问实际的表。
下面举的例子中,GudiNo, StoreId列都有单独的索引。




