
& # 8203;在微服务架构中,我们将系统拆分成了若干弱小的单元,单元与单元之间通过HTTP或TCP等者方式相互访问,各单元的应用间通过服务注册与订阅的方式相互依赖。由于每个单元都在不同的进程中运行,依赖<代码>远程调用的方式执行,这样就可能引起因为网速变慢或者网络故障导致请求变慢或超时,若此时调用方的请求在不断增加,最后就会因等待出现故障的依赖方响应形成任务积压,最终导致自身服务的瘫痪。
& # 8203;<代码> Hystrix>
& # 8203;在微服务架构中,存在着许多的服务单元,若单一节点的故障,就很容易因为依赖关系而引发故障的蔓延,最终导致整个生态系统的瘫痪。为了解决这样的问题,产生了<代码>断路器>
& # 8203;在<代码>分布式架构中>
雪崩效应
& # 8203;雪崩效应就像是水滴石穿,蝴蝶效应一样,是指微小的事物随着时间的推移,会变得越来越巨大,从而对整个环境造成影响的现象,例如:在生态系统中,某一类物种的灭绝可能对整个生态系统造成不了太大的损失,但是这类物种的灭绝可能会引发其他物种的死亡,其他物种的灭绝又会影响另外一种物种的灭亡,就像雪球越滚越大,最终会导致整个生态系统的崩溃。
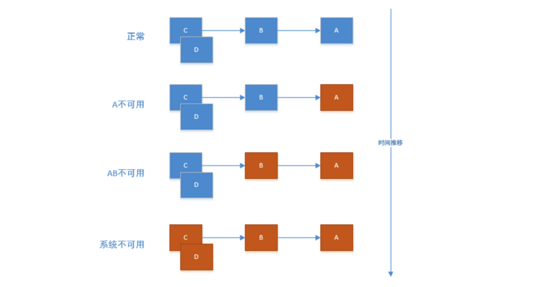
如上图所示:作为服务提供者,B为A的服务消费者,C和D是B的服务消费者。不可用引起了B的不可用,并将不可用像滚雪球一样放大到C和D时,雪崩效应就形成了。
<代码>流量激增>
<代码>缓存刷新:假设为客户端,B为服务器端,假设一个系统请求都流向B系统,请求超出了B系统的承载能力,就会造成B系统崩溃
<代码>连接未释放:代码循环调用的逻辑问题,资源未释放引起的内存泄漏等问题;
<代码>硬件故障>
<代码>线程同步等待>
<强>
& # 8203;针对上述的雪崩问题,每一条都有一个自己的解决方案,但是任何一个解决方案能够应对所有场景
-
<李>针对流量激增,采用自动扩容以应对流量激增,或者在负载均衡器上安装限流模块李
<李>针对缓存刷新,参考缓存应用的服务过载案例研究李
<李>针对硬件故障,采用多机房灾备,跨机房路由李
<李>针对同步等待,采用线程隔离,熔断器等机制李
通过实践发现,线程同步等待是最常见引发的雪崩效应的场景。
& # 8203;在开始使用春云Hystrix断路器之前,我们先用之前实现的一些内容作为基础,构建一个如下图所示的服务调用关系:
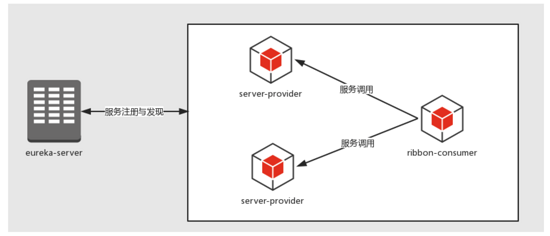
如图所示,上面需要的角色有三个,服务有四个
-
<李> ribbon-connsumer:带消费者,消费服务器供应商提供的服务李
<李> server提供者:服务提供者,提供服务供消费者消费(有点像父母默默的付出一样),启动两个实例,还记得怎么启动吗? - server。李港启动
<李> eureka-server:尤里卡注册中心,提供最基本的订阅发布功能。消费者和服务提供者都需要往注册中心注册自己
李
& # 8203;依次启动上面的四个服务,发现注册中心已经成功注册了四个服务(包括自己)




