需求的是:针对三篇英文文章进行分析,计算出现次数最多的10个单词
逻辑很清晰简单,不算难,使用python读取多个txt文件,将文件的内容写入新的txt中,然后对新txt文件进行词频统计,得到最终结果。
代码如下:(在Windows 10, Python 3.7.4环境下运行通过)
#=utf - 8编码
进口再保险
进口操作系统
#获取源文件夹的路径下的所有文件
Python sourceFileDir=' D: \ \ \ \ txt \ \ '
文件名=os.listdir (sourceFileDir)
#打开当前目录下的结果。txt文件,如果没有则创建
#文件也可以是其他类型的格式,如result.js
Python文件=打开(' D: \ \ \ \结果。txt”、“w”)
# 遍历文件
文件名的文件名:
filepath=sourceFileDir + ' \ \ ' +文件名
#遍历单个文件,读取行数,写入内容
行开放(filepath):
file.writelines(线)
file.write (“\ n”)
#关闭文件
file.close ()
#获取单词函数定义
def getTxt ():
txt=开放(result.txt) .read ()
txt=txt.lower ()
txt=三种。替换(“”、“\”)
“@ # $ % ^ # !,* ()+”/:;& lt;=祝辞& # 63;@ [\ \]_ ~ {|}
的ch ' !”@ # $ % ^, * () +, -/:; & lt;=祝辞& # 63;@ [\ \]_ ~ {|}”:
三种。替换(ch’、‘)
返回三种
# 1。获取单词
hamletTxt=getTxt ()
# 2。切割为列表格式”,兼容符号错误情况,只保留英文单词
txtArr=re.findall (“[a - z \“a - z) +”, hamletTxt)
# 3。去除所有遍历统计
数量={}
在txtArr:
#去掉一些常见无价值词
forbinArr=['。',' ',' ','我']
如果单词不在forbinArr:
数(字)=?词,0)+ 1
# 4。转换格式、方便打印,将字典转换为列表,次数按从大到小排的序
countsList=列表(counts.items ())
countsList。sort(关键=λx: x[1],反向=True)
# 5。输出结果
因为我在范围(10):
词数=countsList[我]
打印(' {0:& lt; 10}{1:在5}’。格式(词数))
之前
效果如下图:
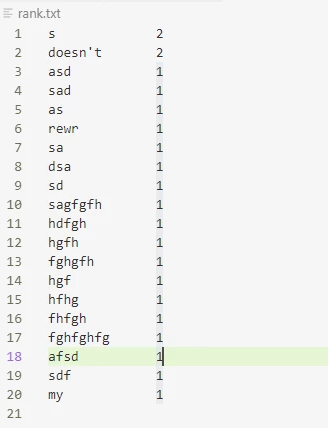
另一种更简单的统计词频的方法:
#=utf - 8编码
从进口计数器集合
#字为读取到的结果
词=[a, b,,“' c ', ' v ', ' 4 ', ', ', ' w ', ' y ', ' y ', ' u ', ' y ', ' r ', ' t ', ' w ']
wordcount=计数器(单词)
print (wordCounter.most_common (10))
#输出:[(' y ', 3), (' a ', 2), (' w ', 2), (' b ', 1), (' c ', 1), (' v ', 1), (' 4 ', 1), (', ', 1), (' u ', 1), (' r ', 1)]
之前
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。





