为了参加某个作秀活动,研究了一波如何结合小程序,科大讯飞实现语音录入,识别的实现。科大讯飞开发文档中只给出Python的演示,并没有给出节点。js的sdk,但问题不大。本文将从小程序相关代码到最后对接科大讯飞api过程,一步步介绍,半个小时,搭建完成小程序语音识别功能!不能再多了!
当然,前提是最好掌握有一点点小程序,节点。js甚至是音频相关的知识。下面话不多说了,来一起看看详细的介绍吧
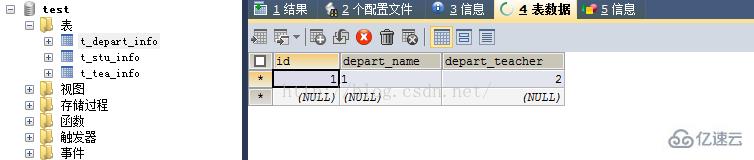
架构比较简单,大伙儿可以先看下图。除了小程序,需要提供3个服务,文件上,传音频编码及对接科大讯飞的服务。
节点。js对接科大讯飞的api, npm上已经有同学提供了sdk,有兴趣的同学可以去搜索了解一下,笔者这里是直接调用了科大讯飞的api接口。
<强> 1,创建小程序
鹅厂的小程序文档非常详细,在这里笔者就不对如何创建一个小程序的步骤进行详细阐述了。有需要的同学可以查看鹅厂的小程序开发文档。
<强> 1.1相关代码
我们摘取小程序里面,语音录入和语音上传部分的代码。
//根据wx提供的api创建录音管理对象
const recorderManager=wx.getRecorderManager ();//监听语音识别结束后的行为
recorderManager。原(recorderResponse=比;{//tempFilePath是录制的音频文件
const {tempFilePath}=recorderResponse;//上传音频文件,完成语音识别翻译
wx.uploadFile ({
url: http://127.0.0.1:7001声音,//该服务在后面搭建。另外,小程序发布时要求后台服务提供https服务!这里的地址仅为开发环境配置。
filePath: tempFilePath,
名称:“文件”,
完成:res=比;{
console.log (res);//我们期待,就是翻译后的内容
}
});
});//开始录音,触发条件可以是按钮或其他,由你自己决定
recorderManager.start ({
持续时间:5000//最长录制时间//其他参数可以默认,更多参数可以查看https://developers.weixin.qq.com/miniprogram/dev/api/media/recorder/RecorderManager.start.html
});
<强> 2,搭建文件服务器
步骤1代码中提到了一个url地址大家应该都还记得。
http://127.0.0.1:7001声音
小程序本身还并没有提供语音识别的功能,所以在这里我们需要借助于“后端”服务的能力,完成我们语音识别翻译的功能。
<强> 2.1鸡蛋。js服务初始化
我们使用鸡蛋。js的cli快速初始化一个工程,当然你也可以使用快递,高雅,巨妖等等框架,框架的选型在此不是重点我们就不做展开阐述了。对鸡蛋。js不熟悉的同学可以查看鸡蛋。js的官网。
npm我egg-init - g
egg-init voice server - type=简单
cd voice server
npm我
安装完成后,执行以下代码
npm运行dev
随后访问浏览器http://127.0.0.1:7001应该可以看到一个嗨,鸡蛋的页面。至此我们的服务初始化完成。
<强> 2.2文件上传接口
a)修改鸡蛋。js的文件上传配置
打开配置/config.default.js添加以下两项配置
模块。出口=appInfo=比;{
…
配置。多部分={
文件大小:2 gb,//限制文件大小
白名单:['。aac ', '。m4a格式”、“。mp3 ']//支持上传的文件后缀名
};
配置。安全={
csrf: {
启用:假//关闭csrf
}
};
…
}
b)添加VoiceController
打开app/controller文件夹,新建文件的声音。js。编写VoiceController使其继承于鸡蛋。js的控制器。具体代码如下:
const控制器=要求(“蛋”)范式;
const fs=要求(fs);
const path=要求(“路径”);
const泵=要求(“mz-modules/泵”);
const uuidv1=要求(uuid/v1);//依赖于uuid库,用于生成唯一文件名,使用npm我uuid安装即可//音频文件上传后存储的路径
const定位路径=路径。解决(__dirname”. .”、“. .”、“上传”);
类VoiceController扩展控制器{
构造函数(params) {
超级(params);
如果(! fs.existsSync(定位路径)){
fs.mkdirSync(定位路径);
}
}
异步翻译(){=this.ctx const部分。多部分({autoFields:真});
让流;
const voicePath=路径。加入(定位路径,uuidv1 ());
而(!isEmpty((流=等待零件()))){
等待泵(流,fs.createWriteStream (voicePath));
}//到这里就完成了文件上传。如果你不需要文件落地,也可以在后续的操作中,直接使用流操作文件流
…//音频编码//科大讯飞语音识别
…
}
}