
如何基于Flink搭建大规模准实时数据分析平台?在Flink前进亚洲2019上,来自Lyft公司实时数据平台的徐赢博士和计算数据平台的高立博士分享了Lyft基于Apache Flink的大规模准实时数据分析平台。
本次分享主要分为四个方面:
-
<李> Lyft的流数据与场景李
<李>准实时数据分析平台和架构李
<李>平台性能及容错深入分析
<李>总结与未来展望李
重要:文末“阅读原文”可查看Flink前进亚洲大会视频。
一、Lyft的流数据与场景
关于Lyft
Lyft是位于北美的一个共享交通平台,和大家所熟知的超级和国内的滴滴类似,Lyft也为民众提供共享出行的服务.Lyft的宗旨是提供世界最好的交通方案来改善人们的生活。
Lyft的流数据场景
Lyft的流数据可以大致分为三类,秒级别,分钟级别和不高于5分钟级别。分钟级别流数据中,自适应定价系统,欺诈和异常检测系统是最常用的,此外还有Lyft最新研发的机器学习特征工程。不高于5分钟级别的场景则包括准实时数据交互查询相关的系统。

Lyft数据分析平台架构
如下图所示的是Lyft之前的数据分析平台架构.Lyft的大部分流数据都是来自于事件,而事件产生的来源主要有两种,分别是手机应用程序和后端服务,比如乘客,司机,支付以及保险等服务都会产生各种各样的事件,而这些事件都需要实时响应。
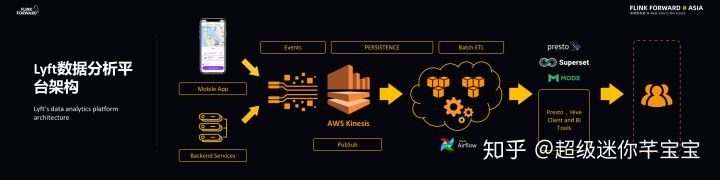
在分析平台这部分,事件会流向AWS的动作上面,这里的动作与Apache卡夫卡非常类似,是一种AWS上专有的PubSub服务,而这些数据流都会量化成文件,这些文件则都会存储在AWS的S3上面,并且很多批处理任务都会弹出一些数据子集。在分析系统方面,Lyft使用的是开源社区中比较活跃的赶快查询引擎.Lyft数据分析平台的用户主要有四种,即数据工程师,数据分析师以及机器学习专家和深度学习专家,他们往往都是通过分析引擎实现与数据的交互。
既往平台的问题
Lyft之所以要基于Apache Flink实现大规模准实时数据分析平台,是因为以往的平台存在一些问题。比如较高的延迟,导入数据无法满足准实时查询的要求,并且基于运动客户机库的流式数据导入性能不足;导入数据存在太多小文件导致下游操作性能不足,数据ETL大多是高延迟多日多步的架构,此外,以往的平台对于嵌套数据提供的支持也不足。

二,准实时数据分析平台和架构
准实时平台架构
在新的准实时平台架构中,Lyft采用Flink实现流数据持久化.Lyft使用云端存储,而使用Flink直接向云端写一种叫做镶花的数据格式,拼花是一种列数据存储格式,能够有效地支持交互式数据查询.Lyft在拼花原始数据上架构实时数仓,实时数仓的结构被存储在蜂房里的表面,蜂巢表的元数据存储在蜂巢metastore里面。
平台会对于原始数据做多级的非阻塞ETL加工,每一级都是非阻塞的(非阻塞),主要是压缩和去重的操作,从而得到更高质量的数据。平台主要使用Apache气流对于ETL操作进行调度。所有的镶花格式的原始数据都可以被很快查询,交互式查询的结果将能够以BI模型的方式显示给用户。
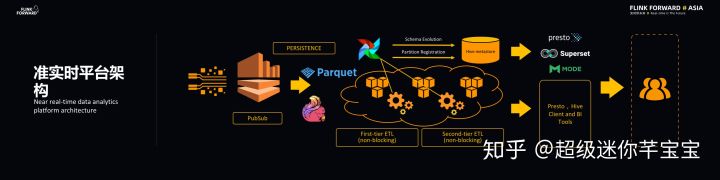
平台设计
Lyft基于Apache Flink实现的大规模准实时数据分析平台具有几个特点:




