
这篇文章将为大家详细讲解有关Python3爬虫实战中爬取豆瓣电影的方法是什么,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
爬虫又称为网页蜘蛛,是一种程序或脚本。
但重点在于,它能够按照一定的规则,自动获取网页信息。
<强>爬虫的基本原理,通用框架
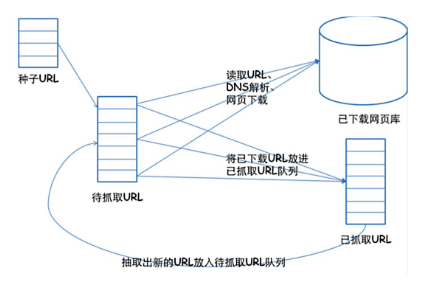
1。挑选种子URL;
2。讲这些URL放入带抓取的URL列队;
3。取出带抓取的URL,下载并存储进已下载网页库中。此外,讲这些URL放入带抓取URL列队,进入下一循环。
4。分析已抓取列队中的URL,并且将URL放入带抓取URL列队,从而进去下一循环。
爬虫获取网页信息和人工获取信息,其实原理是一致的。
如我们要获取电影的“评”分信息

<强>人工操作步骤:
1。获取电影信息的网页;
2。定位(找到)要评分信息的位置;
3。复制,保存我们想要的评分数据。
<强>爬虫操作步骤:
1。请求并下载电影页面信息;
2。解析并定位评分信息;
3。保存评分数据。
<强>爬虫的基本流程
简单来说,我们向服务器发送请求后,会得到返回的页面,通过解析页面后,我们可以抽取我们想要的那部分信息,并存储在指定文档或数据库中,这样,我们想要的信息会被我们“爬”下来了。
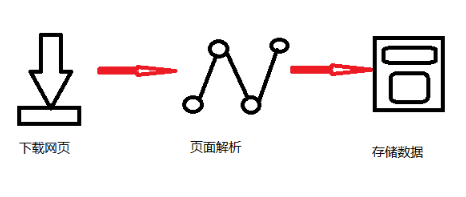
python中用于爬虫的包很多,如bs4, urllib,请求等等。这里我们用请求+ xpath的方式,因为简单易学,像BeautifulSoup还是有点难的。
下面我们就使用请求和xpath来爬取豆瓣电影中的“电影名”,“导演”,“演员”、“评分”等信息。
安装请求和lxml库:
<强>一、导入模块
<强>二,获取豆瓣电影目标网页并解析
爬取豆瓣电影《神秘巨星》上的一些信息,地址
https://movie.douban.com/subject/26942674/?=显示
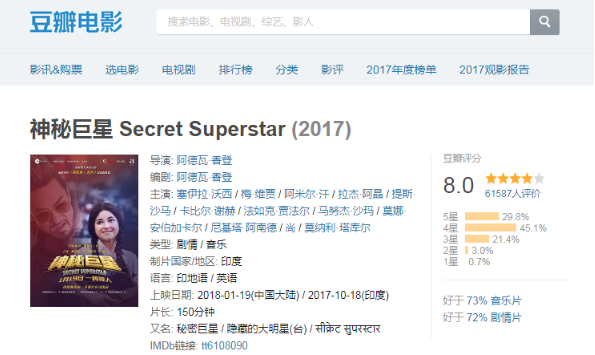
<强> 1。获取电影名称。
获取电影的xpath信息并获得文本
这里的xpath信息要手动获取,获取方式如下:
1。如果你是用谷歌浏览器的话,鼠标“右键”→“检查元素”,
2. ctrl + Shift + C将鼠标定位到标题;
3。“右键”→“复制”→“复制xpath”就可以复制xpath。
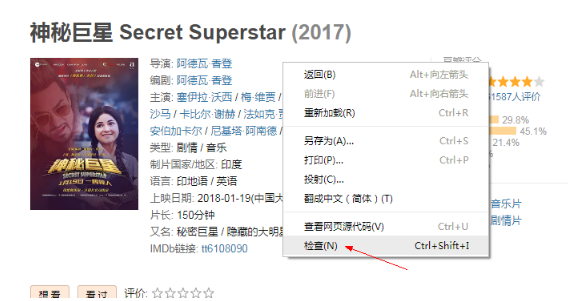
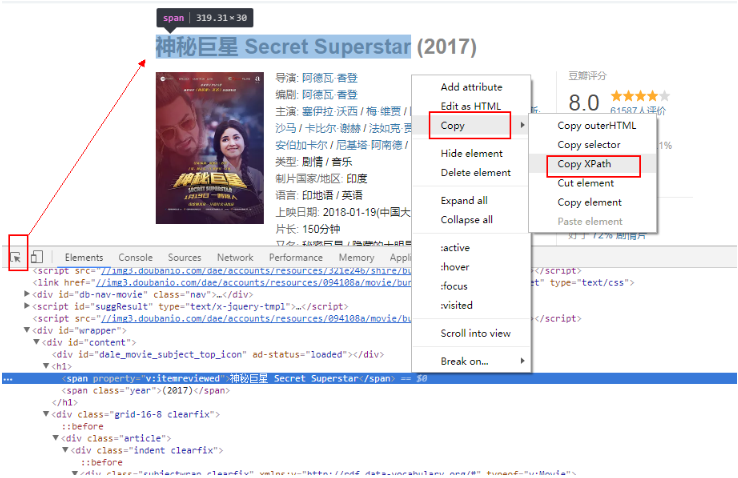
这样,我们就把电影标题的xpath信息复制下来了。
放到代码中并打印信息




