
小编给大家分享一下关于Python3爬虫中选择器的用法,相信大部分人都还不怎么了解,因此分享这篇文章给大家学习,希望大家阅读完这篇文章后大所收获、下面让我们一起去学习方法吧!
<强>选择器的用法
我们之前介绍了利用美丽的汤,pyquery以及正则表达式来提取网页数据,这确实非常方便。而Scrapy还提供了自己的数据提取方法,即选择器(选择器).Selector是基于lxml来构建的,支持XPath选择器,CSS选择器以及正则表达式,功能全面,解析速度和准确度非常高。
本节将介绍选择器的用法。
<强> 1。直接使用
选择器是一个可以独立使用的模块。我们可以直接利用选择器这个类来构建一个选择器对象,然后调用它的相关方法如xpath (), css()等来提取数据。
例如,针对一段HTML代码,我们可以用如下方式构建选择器对象来提取数据:
运行结果:
我们在这里没有在Scrapy框架中运行,而是把Scrapy中的选择器单独拿出来使用了,构建的时候传入文本参数,就生成了一个选择器选择器对象,然后就可以像前面我们所用的Scrapy中的解析方式一样,调用xpath (), css()等方法来提取了。
在这里我们查找的是源代码中的标题中的文本,在xpath选择器最后加文本()方法就可以实现文本的提取了。
以上内容就是选择器的直接使用方式。同美丽的汤等库类似,选择其实也是强大的网页解析库。如果方便的话,我们也可以在其他项目中直接使用选择器来提取数据。
接下来,我们用实例来详细讲解选择器的用法。
<强> 2。Scrapy壳
由于选择器主要是与Scrapy结合使用,如Scrapy的回调函数中的参数响应直接调用xpath()或者css()方法来提取数据,所以在这里我们借助Scrapy壳来模拟Scrapy请求的过程,来讲解相关的提取方法。
我们用官方文档的一个样例页面来做演示:http://doc.scrapy.org/en/latest/_static/selectors-sample1.html。
开启Scrapy壳,在命令行输入如下命令:
我们就进入到Scrapy壳模式。这个过程其实是,Scrapy发起了一次请求,请求的URL就是刚才命令行下输入的URL,然后把一些可操作的变量传递给我们,如请求、响应等,如图13比5所示。
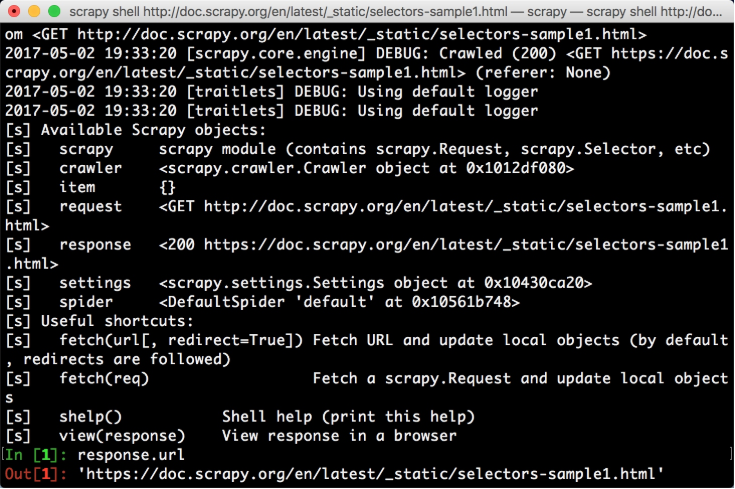
图13比5 Scrapy壳
我们可以在命令行模式下输入命令调用对象的一些操作方法,回车之后实时显示结果。这与Python的命令行交互模式是类似的。
接下来,演示的实例都将页面的源码作为分析目标,页面源码如下所示:

