
小编给大家分享一下pyspider的使用方法,相信大部分人都还不怎么了解,因此分享这篇文章给大家学习,希望大家阅读完这篇文章后大所收获、下面让我们一起去学习方法吧!
<强> pyspider的基本使用
本节用一个实例来讲解pyspider的基本用法。
<强> 1。本节目标
我们要爬取的目标是去哪儿网的旅游攻略,链接为http://travel.qunar.com/travelbook/list.htm,我们要将所有攻略的作者,标题,出发日期,人均费用,攻略正文等保存下来,存储到MongoDB中。
<强> 2。准备工作
请确保已经安装好了pyspider和PhantomJS,安装好了MongoDB并正常运行服务,还需要安装PyMongo库,具体安装可以参考第1章的说明。
<强> 3。启动pyspider
执行如下命令启动pyspider:
运行效果如图12所示。
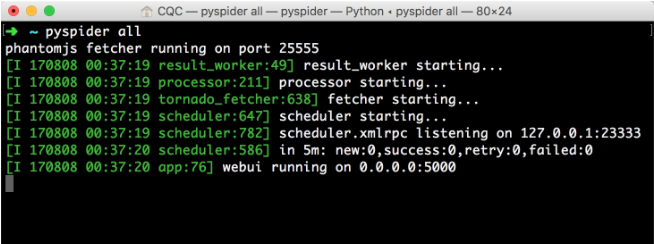
图12运行结果
这样可以启动pyspider的所有组件,包括PhantomJS, ResultWorker,制造者,取物,调度器,WebUI,这些都是pyspider运行必备的组件。最后一行输出提示WebUI运行在5000端口上。可以打开浏览器,输入链接http://localhost: 5000年,这时我们会看到页面,如图12所示。
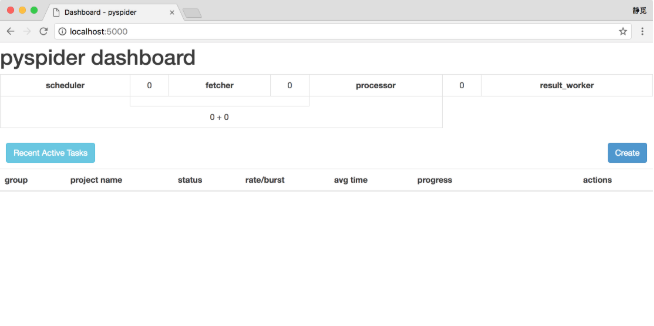
图12 WebUI页面
此页面便是pyspider的WebUI,我们可以用它来管理项目,编写代码,在线调试,监控任务等。
<强> 4。创建项目
新建一个项目,点击右边的创建按钮,在弹出的浮窗里输入项目的名称和爬取的链接,再点击创建按钮,这样就成功创建了一个项目,如图以所示。
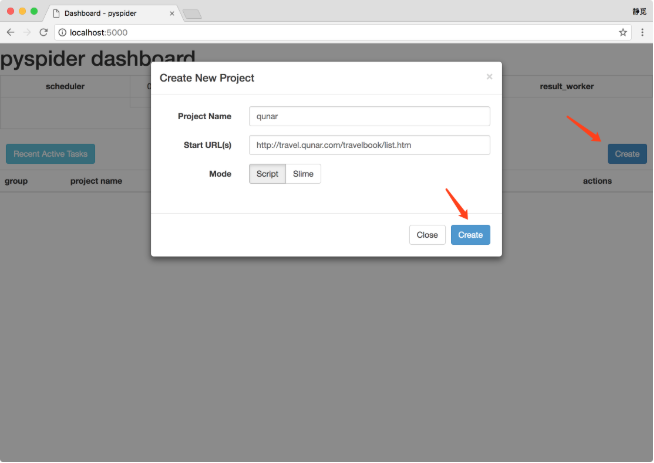
图以创建项目
接下来会看到pyspider的项目编辑和调试页面,如图后所示。

图赔率调试页面
左侧就是代码的调试页面,点击左侧右上角的跑单步调试爬虫程序,在左侧下半部分可以预览当前的爬取页面。右侧是代码编辑页面,我们可以直接编辑代码和保存代码,不需要借助于IDE。
注意右侧,pyspider已经帮我们生成了一段代码,代码如下所示:
这里的处理程序就是pyspider爬虫的主类,我们可以在此处定义爬取,解析,存储的逻辑。整个爬虫的功能只需要一个处理程序即可完成。
接下来我们可以看到一个crawl_config属性。我们可以将本项目的所有爬取配置统一定义到这里,如定义头,设置代理等,配置之后全局生效。
然后,on_start()方法是爬取入口,初始的爬取请求会在这里产生,该方法通过调用爬行()方法即可新建一个爬取请求,第一个参数是爬取的URL,这里自动替换成我们所定义的URL.crawl()方法还有一个参数回调,它指定了这个页面爬取成功后用哪个方法进行解析,代码中指定为index_page()方法,即如果这个URL对应的页面爬取成功了,那反应将交给index_page()方法解析。
index_page()方法恰好接收这个响应参数,反应对接了pyquery。我们直接调用doc()方法传入相应的CSS选择器,就可以像pyquery一样解析此页面,代码中默认是一个(href ^=癶ttp”),也就是说该方法解析了页面的所有链接,然后将链接遍历,再次调用了爬行()方法生成了新的爬取请求,同时再指定了回调为detail_page,意思是说这些页面爬取成功了就调用detail_page()方法解析。这里,index_page()实现了两个功能,一是将爬取的结果进行解析,二是生成新的爬取请求。
detail_page()同样接收响应作为参数.detail_page()抓取的就是详情页的信息,就不会生成新的请求,只对反应对象做解析,解析之后将结果以字典的形式返回。当然我们也可以进行后续处理,如将结果保存到数据库。




