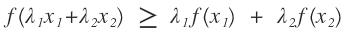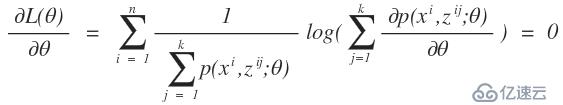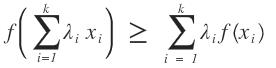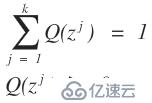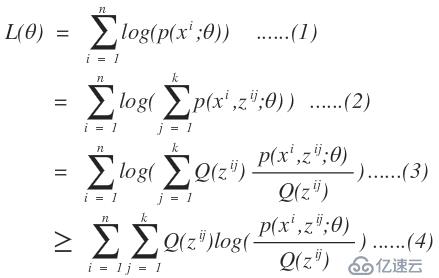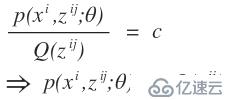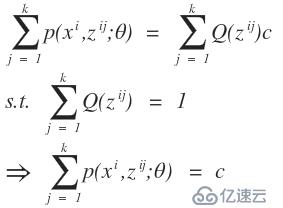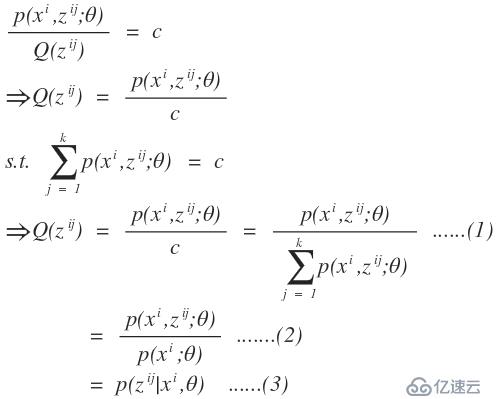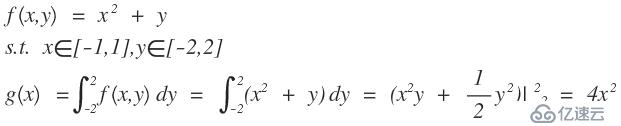,那么我们在用k-means算法时就变得很简单了,直接求出这k个质心,而不用我们所熟知的k-means算法的计算步骤。之所以我们使用我们所熟知的k-means算法的步骤,那是因为我们不知道每个样本应该归属于哪个类以及他们存在多少个聚类中心比较合适。那么这个隐变量就是每一个样本应该归属于哪个类。在举一个例子,高斯混合模型,这个是典型用到了EM算法的思想,如果对这个模型不太清楚,可以网上查资料。同样,我们也有这样一批数据,在采样中,我们就已经知道k和每个样本应该属于哪个类,那么我们所要做的工作就是把每一类数据拿出来,直接通过均值和方差就可以求出每一个高斯函数的模型了,而不需要再进行EM算法通过最大似然估计来计算我们的高斯混合模型参数了。而现实的应用中是我们不知道这样的一批数据应该分为几个类以及每一个样本应该属于哪一个类,那么这就是隐变量。这样的问题和先有鸡还是先有蛋的问题差不多,当我们知道数学模型的参数后,我们就知道了样本应该属于哪个类,同时当我们知道隐变量后,我们也就知道样本属于哪个类,从而得到数学模型的参数,但是不幸的是在开始的时候我们只有样本,隐变量和模型参数都不知道。


区间