<强>压缩原因
1。文件太大,节省空间
2。提高数据在网络上传输的效率
3。对数据起到保护作用- - - - - -加密
<强>文件压缩类型
无损压缩:源文件被压缩之后,可以通过解压缩还原成与源文件相同的格式
有损压缩:源文件被压缩之后,解压缩无法还原成与源文件相同,但识别其内容没有影响,多用于语音、图片,视频压缩
<>强基于哈夫曼树的压缩如何实现
通过霍夫曼编码实现,字符一般都是以字节存储的,通过编码转换为二进制编码(1字节=8比特位)
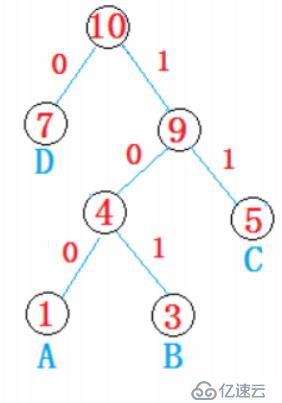
<强>首先,什么是霍夫曼树
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
例如:给定权值为1 (A), 3 (B)、5 (C), 7 (D)四个节点,构建霍夫曼树
 基于哈夫曼树的文件压缩项目
基于哈夫曼树的文件压缩项目





