
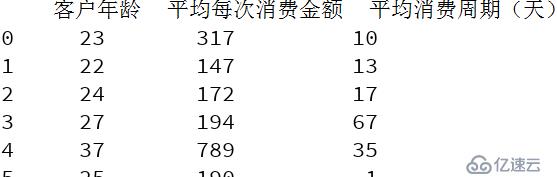
导入超市用户的数据
熊猫作为pd导入从sklearn
。预处理进口StandardScaler #标准差标准化
com=pd.read_csv (“。/company.csv”,编码=' ansi)
<中心>
导入剔除异常值的函数
def box_analysis(数据):
"
进行箱线图分析,剔除异常值
: param数据:
:返回:
"
瞿=data.quantile (0.75)
ql=data.quantile (0.25)
差=曲- ql
#上限与下限1.5可以微调
=曲+ 1.5 *差
低=ql - 1.5 *差
#进行比较运算
bool_id_1=data<=
bool_id_2=data>=低
bool_num=bool_id_1和;bool_id_2
返回bool_num
进行缺失值检测
打印(com.isnull () .sum ())
检测结果无缺失值
筛选有用特征,切片处理
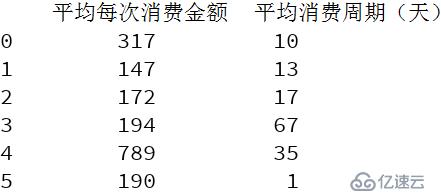
data=https://www.yisu.com/zixun/com.iloc [: 2:]
<中心>
箱线图分析来进行异常值检测
按照平均每次消费金额进行异常值去除
bood_id_1=box_analysis (data.iloc [: 0])
data=https://www.yisu.com/zixun/data.loc [bood_id_1:]
按照平均消费周期进行异常值去除
bood_id_2=box_analysis (data.iloc [:, 1])
data=https://www.yisu.com/zixun/data.loc [bood_id_2:]
构建需要特征
数据。loc[::“每日消费金额”)=data.loc(:,“平均每次消费金额']/data.loc(:,“平均消费周期(天)”)
标准化数据,量级不大,暂时不处理量级
=StandardScaler站()#创建标准差示例
#先计算每一列的均值,标准差再进行转化数据
x=stand.fit_transform(数据)#进行标准化
把上面数据处理部分封装进函数
def built_data ():
#缺失值检测
#打印(com.isnull () .sum ())
#筛选有用特征,切片处理
data=https://www.yisu.com/zixun/com.iloc [: 2:]
#打印(数据)
#异常值检测,箱线图分析
#按照平均每次消费金额进行异常值去除
bood_id_1=box_analysis (data.iloc [: 0])
data=https://www.yisu.com/zixun/data.loc [bood_id_1:]
#按照平均消费周期进行异常值去除
bood_id_2=box_analysis (data.iloc [:, 1])
data=https://www.yisu.com/zixun/data.loc [bood_id_2:]
#构建需要特征
数据。loc[::“每日消费金额”)=data.loc(:,“平均每次消费金额']/data.loc(:,“平均消费周期(天)”)
#打印(数据)
#标准化数据,量级不大,暂时不处理量级
#标准化数据
=StandardScaler站()#创建标准差示例
#先计算每一列的均值,标准差再进行转化数据
x=stand.fit_transform(数据)#进行标准化
返回数据。值
绘图部分函数如下
def show_res_km(数据、y_predict中心):
"
进行结果展示
: param数据:原始数据
: param y_predict:预测标签
: param中心:最终的聚类中心
:返回:
"
plt.figure ()
#获取原始数据的行数
index_num=数据。形状[0]
#
颜色=[‘r’,‘g’, ' b ', ' y ']
我的范围(index_num):
plt.scatter([0]我,数据[1]我,c=颜色(int (y_predict[我])))
#散点图的绘制,一个一个绘制
#聚类中心的位置
# b的话是描点划线,bx的话是画点但是不描线
plt.plot(中心:0,中心(:1),“软”,标志=皒”, markersize=12)
plt.show ()
调用函数来进行聚类
data=https://www.yisu.com/zixun/built_data ()
#导包实现
k=3公里=KMeans (n_clusters=k)
#训练数据
km.fit(数据)
#进行预测,y_predict预测标签
y_predict=km.predict(数据)
#获取聚类中心
中心=公里。cluster_centers_
打印(“预测值:\ n”, y_predict)
打印(“聚类中心:\ n”,中心)
show_res_km (data.values y_predict,中心)
得出结果




