
前言
初因是给宝宝制作拼音卡点读包时,要下载卖家提供给的MP3,大概有2百多个。作为一个会码代码的非专业人士,怎么可能取一个一个下载?所以就决定用python的scrapy框架写个爬虫,去下载这些MP3。一开始以为简单,直到完成下载,竟然花了我一下午的时间。最大的难题就是页面的数据是通过javascript脚本动态渲染的。百度上大部分方法都是通过飞溅做中转实现的方法,而我只是想简单的写个代码实现而已,看飞溅还要挂码头工人,巴啦巴啦一大堆的操作,顿时就心塞了。通过百度和自己实践,终于找到了一个最简单的方法解决了问题,特此记录下来,同大家分享一下。
页面分析
先开始分析目标html
首页
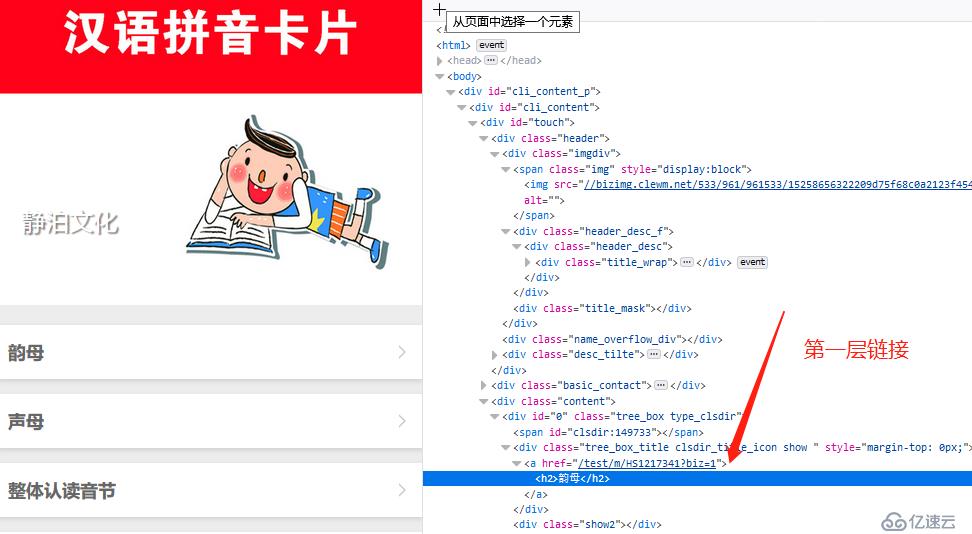
韵母列表页
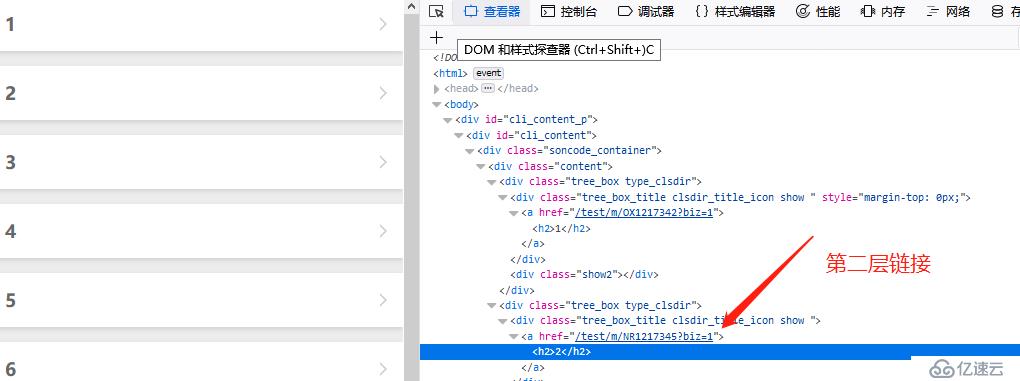
拼音e MP3页
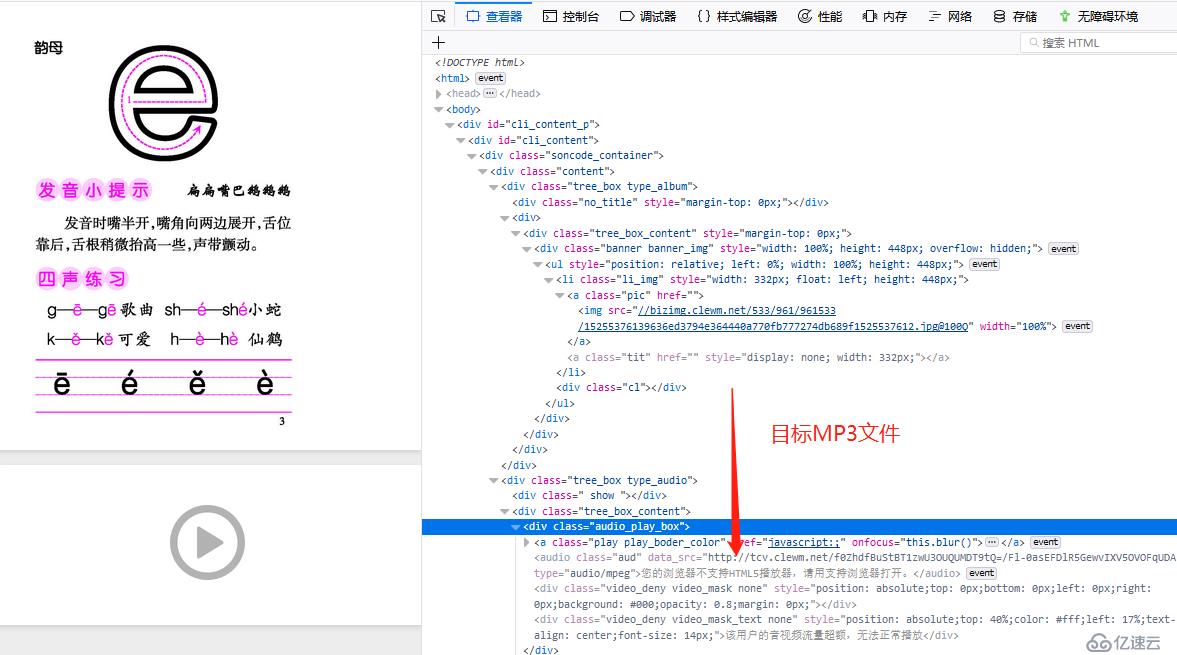
看着简单吧,可一爬取,问题立马就出现了,旋度下静态页看看。
curl - s https://biz.cli.im/test/CI525711?少许=2的在111年。html
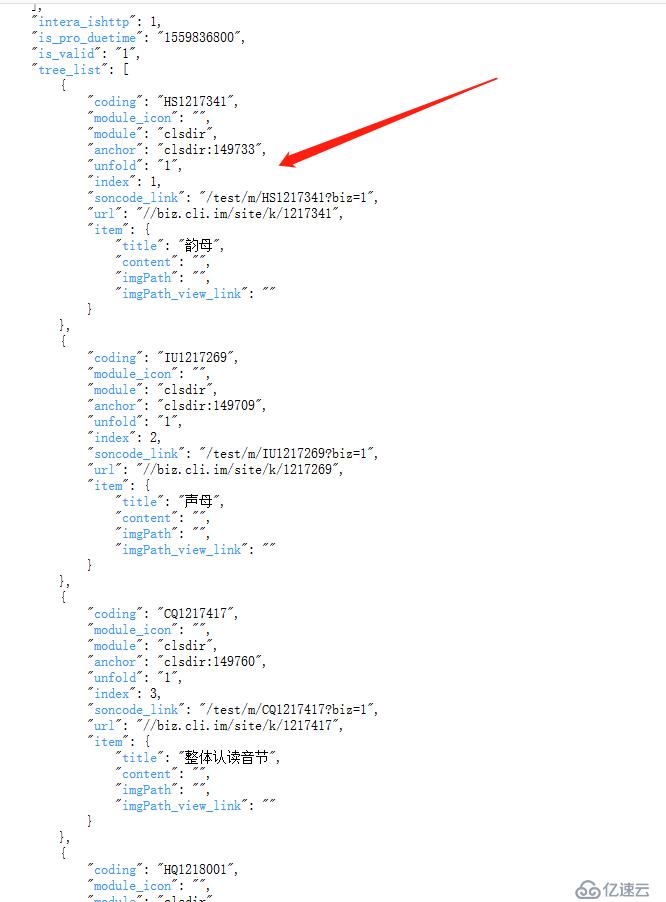
首页竟是这样的,页面的列表数据,是通过javascript动态渲染的。
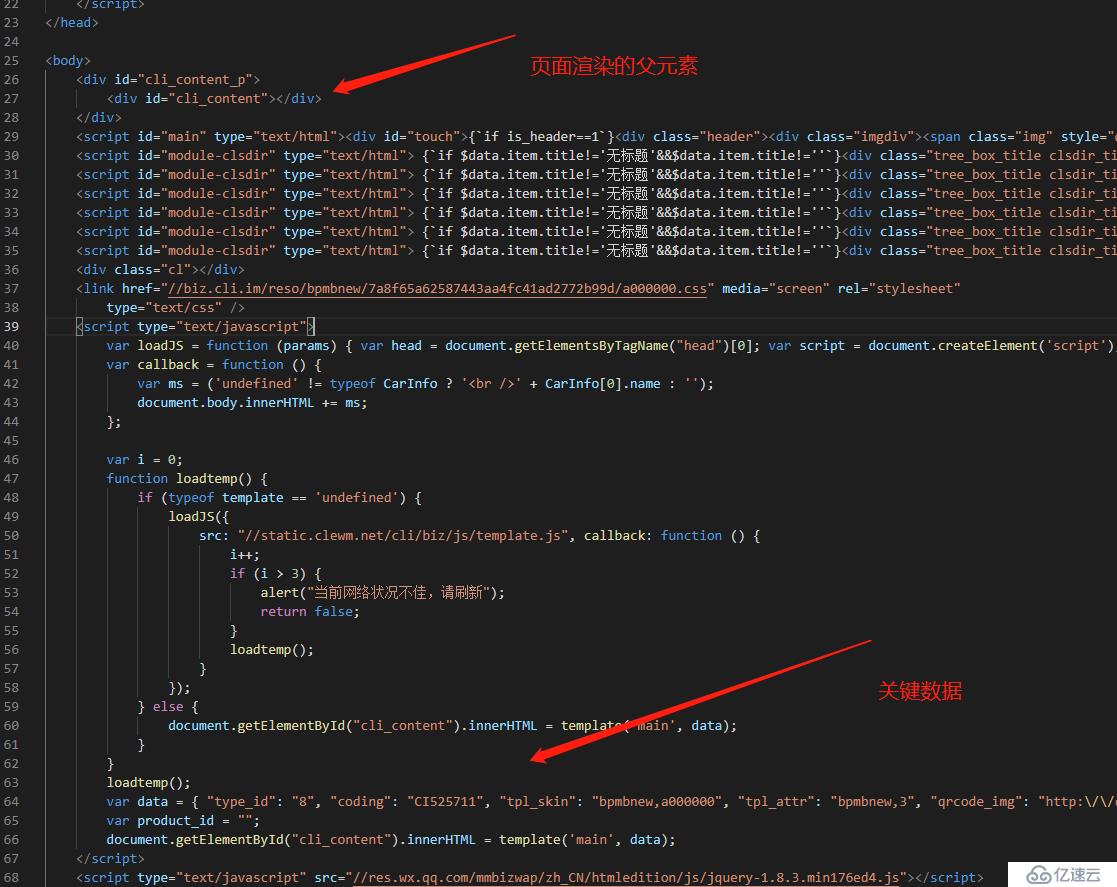
是个json数据,再格式化后分析下,页面链接都在数据这个json数据里了。
代码实现
最基础的反应。xpath方式是不能用了,我的思路是把脚本获取出来,然后用获取soncode_link的值。
经过研究决定用BeautifulSoup + js2xml
<代码>类JingboSpider (scrapy.Spider):
name='镜泊湖
allowed_domains=(“biz.cli.im”)
all_urls=" https://biz.cli.im "
start_urls=[“测试/CI525711 ?少许=2”)
def start_requests(自我):
#自定义头
在self.start_urls url:
收益scrapy.Request(自我。all_urls + " + url,标题={“用户代理”:USER_AGENT})
def解析(自我,反应):
resp=response.text
#用lxml作为解析器,解析返回数据
lxml的汤=BeautifulSoup(职责)
#获取所有脚本标签数据,并遍历查找
脚本=soup.find_all(脚本)
脚本的脚本:
如果类型(script.string)类型(一):
继续
如果script.string.find (“loadtemp();”)在0:
src=https://www.yisu.com/zixun/script
打破
title=氨晏狻?
链接=" soncode_link "
#将js数据转化为xml标签树格式
src_text=js2xml.parse (src。字符串编码=皍tf - 8”, debug=False)
src_tree=js2xml.pretty_print (src_text)
#打印(src_tree)
选择器=etree.HTML (src_tree)
连接=选择器。xpath(“//财产[@ name=' +链接+ " ']/字符串/text ()”)
playurl=选择器。xpath (“[@ name=' play_url ']//属性/字符串/text ()”)
标题=选择器。xpath(“//财产[@ name=' +标题+ " ']/字符串/text ()”)
#剩下就是循环获取页面,下载MP3文件了。
scrapy环境安装
wget https://www.lfd.uci.edu/gohlke/pythonlibs/扭曲? 18.9.0 ? cp37 ? cp37m ? win_amd64.whl
wget https://www.lfd.uci.edu/gohlke/pythonlibs/beautifulsoup4 ? 4.7.1 ? py3吗?没有? any.whl
pip安装扭曲18.9.0 ? cp37 ? cp37m ? win_amd64。whl
pip安装pypiwin32 js2xml urllib2 Scrapy
创建项目h5>
scrapy startproject拼音
创建任务h5> scrapy genspider镜泊湖https://biz.cli.im/test/CI525711?stime=2
开始爬取
scrapy爬镜泊湖
最后战果

参考文档
https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
https://www.cnblogs.com/zhaof/p/6930955.html https://blog.csdn.net/qq_34246164/article/details/80700399




