介绍 import 请求
import json
得到bs4 import BeautifulSoup
import pandas as pd
class bus_stop:
,# #定义一个类,用来获取每趟公交的站点名称和经纬度
自我,def __init__ ():=,self.url & # 39; https://guiyang.8684.cn/line {} & # 39;=,self.starnum []
,for start_num 拷贝范围(1,17):
,self.starnum.append (start_num)=,self.payload , {}
,self.headers =, {
,& # 39;饼干# 39;:,& # 39;JSESSIONID=48304 f9e8d55a9f2f8acc14b7ec5a02d& # 39;}
,# #调用高德api获取公交线路的经纬度
,# # #这个关键大家可以自己去申请
,def get_location(自我,,行):=,url_api & # 39; https://restapi.amap.com/v3/bus/linename?s=rsv3&扩展=all&关键=559 bdffe35eec8c8f4dae959451d705c&输出=json&城市=贵阳,抵消=2,关键词={},平台=js # 39; .format (
,线)=,,res requests.get (url_api)。text
,#打印(res),可以用于检验传回的信息里面是否有自己需要的数据=,,rt json.loads (res)=,dicts rt (& # 39; buslines& # 39;] [0]
,#返回df对象=,,df pd.DataFrame.from_dict((字典))
return df
,# #获取每趟公交的站点名称
,def get_line(自我):
,for start self.starnum拷贝:=,,start str(开始)
,#构造url=,,url self.url.format(开始)=,,res requests.request (
,“GET", url,标题=self.headers, data=https://www.yisu.com/zixun/self.payload)
汤=BeautifulSoup (res。文本,“lxml”)
div=汤。找到(div, class_=clearfix列表)
列表=div.find_all (' a ')
项的列表:
行=项目。文本#获取一个标签下的公交线路
lines.append(线)
返回行
if __name__==癬_main__”:
bus_stop=bus_stop ()
stop_df=pd.DataFrame ([])
行=[]
bus_stop.get_line ()
#输出路线
打印(“一共有{}条公交路线”.format (len(线)))
打印(线)
#异常处理
error_lines=[]
线的线:
试一试:
df=bus_stop.get_location(线)
stop_df=pd。concat ([stop_df, df)轴=0)
除了:
error_lines.append(线)
#输出异常的路线
打印(“异常路线有{}条公交路线”.format (len (error_lines)))
打印(error_lines)
#输出文件大小
打印(stop_df.shape)
stop_df.to_csv (“bus_stop。csv”,编码=' gbk,指数=False) # #,我们需要处理的公共汽车站列和ID列
时间=data stop_df [[& # 39; id # 39; & # 39; busstops& # 39;]]
data.head () # #,字典或者列表分列
时间=df_pol data.copy ()
# # #,设置索引列
df_pol.set_index (& # 39; id # 39;,原地=True)
df_pol.head ()
本篇内容介绍了“怎么利用python爬取城市公交站点”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
页面分析https://guiyang.8684.cn/line1


爬虫
我们利用请求请求,利用BeautifulSoup来解析,获取我们的站点数据。得到我们的公交站点以后,我们利用高德api来获取站点的经纬度坐标,利用熊猫解析json文件。接下来开干,我推荐使用面向对象的方法来写代码。

数据清洗
我们先来看效果,我需要对公共汽车站列进行清洗。我们的总体思路,分列→逆透视→分列。我会接受两种方法,一是Excel PQ,二是python。
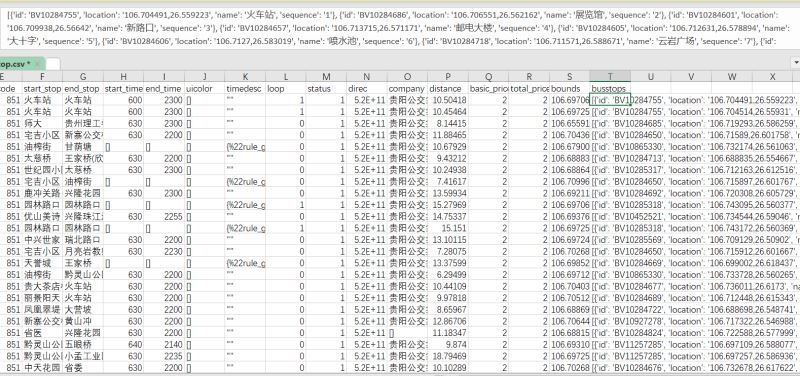
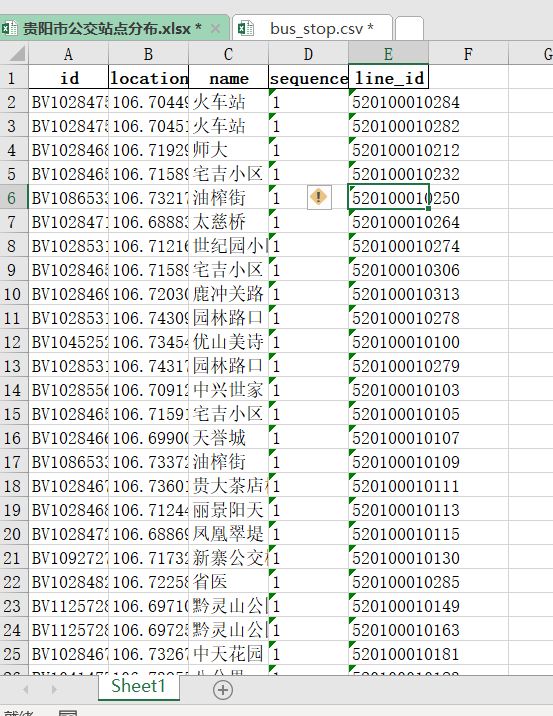
Excel PQ数据清洗
这一方法完全利用PQ,纯界面操作,问题不大,所以我们看看流程就可以了,核心步骤就是和上面一样的。
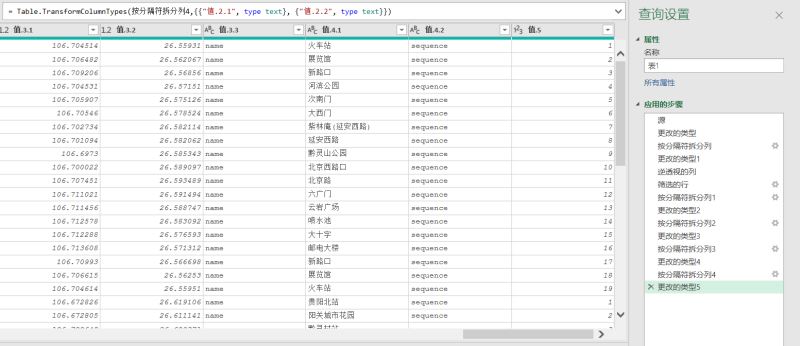
python数据清洗