
这篇文章主要介绍了如何使用PyTorch搭建CNN实现风速预测,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
数据集

数据集为Barcelona某段时间内的气象数据,其中包括温度、湿度以及风速等。本文将利用CNN来对风速进行预测。
特征构造
对于风速的预测,除了考虑历史风速数据外,还应该充分考虑其余气象因素的影响。因此,我们根据前24个时刻的风速+下一时刻的其余气象数据来预测下一时刻的风速。
一维卷积
我们比较熟悉的是CNN处理图像数据时的二维卷积,此时的卷积是一种局部操作,通过一定大小的卷积核作用于局部图像区域获取图像的局部信息。图像中不同数据窗口的数据和卷积核做inner product(内积)的操作叫做卷积,其本质是提纯,即提取图像不同频段的特征。
上面这段话不是很好理解,我们举一个简单例子:
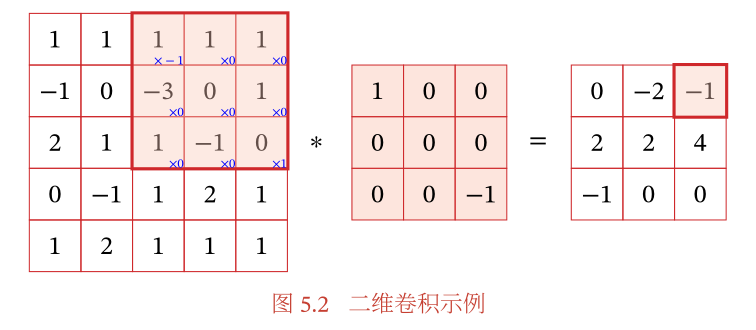
假设最左边的是一个输入图片的某一个通道,为5 × 5 5 \times55×5,中间为一个卷积核的一层,3 × 3 3 \times33×3,我们让卷积核的左上与输入的左上对齐,然后整个卷积核可以往右或者往下移动,假设每次移动一个小方格,那么卷积核实际上走过了一个3 × 3 3 \times33×3的面积,那么具体怎么卷积?比如一开始位于左上角,输入对应为(1, 1, 1;-1, 0, -3;2, 1, 1),而卷积层一直为(1, 0, 0;0, 0, 0;0, 0, -1),让二者做内积运算,即1 * 1+(-1 * 1)= 0,这个0便是结果矩阵的左上角。当卷积核扫过图中阴影部分时,相应的内积为-1,如上图所示。
因此,二维卷积是将一个特征图在width和height两个方向上进行滑动窗口操作,对应位置进行相乘求和。
相比之下,一维卷积通常用于时序预测,一维卷积则只是在width或者height方向上进行滑动窗口并相乘求和。 如下图所示:
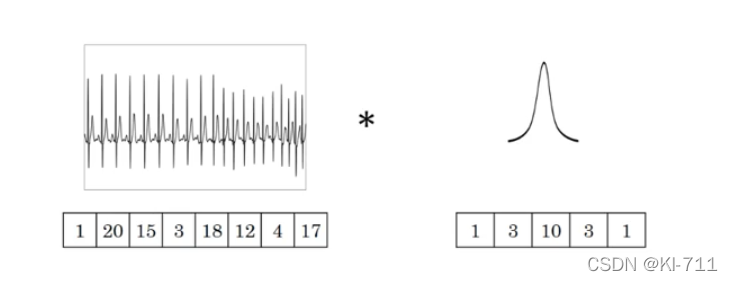
原始时序数为:(1, 20, 15, 3, 18, 12. 4, 17),维度为8。卷积核的维度为5,卷积核为:(1, 3, 10, 3, 1)。那么将卷积核作用与上述原始数据后,数据的维度将变为:8-5+1=4。即卷积核中的五个数先和原始数据中前五个数据做卷积,然后移动,和第二个到第六个数据做卷积,以此类推。
数据处理
1.数据预处理
数据预处理阶段,主要将某些列上的文本数据转为数值型数据,同时对原始数据进行归一化处理。文本数据如下所示:
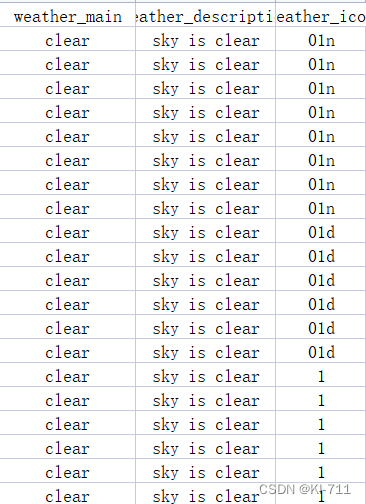
经过转换后,上述各个类别分别被赋予不同的数值,比如"sky is clear"为0,"few clouds"为1。
def load_data():
global Max, Min
df = pd.read_csv('Barcelona/Barcelona.csv')
df.drop_duplicates(subset=[df.columns[0]], inplace=True)
# weather_main
listType = df['weather_main'].unique()
df.fillna(method='ffill', inplace=True)
dic = dict.fromkeys(listType)
for i in range(len(listType)):
dic[listType[i]] = i
df['weather_main'] = df['weather_main'].map(dic)
# weather_description
listType = df['weather_description'].unique()
dic = dict.fromkeys(listType)
for i in range(len(listType)):
dic[listType[i]] = i
df['weather_description'] = df['weather_description'].map(dic)
# weather_icon
listType = df['weather_icon'].unique()
dic = dict.fromkeys(listType)
for i in range(len(listType)):
dic[listType[i]] = i
df['weather_icon'] = df['weather_icon'].map(dic)
# print(df)
columns = df.columns
Max = np.max(df['wind_speed']) # 归一化
Min = np.min(df['wind_speed'])
for i in range(2, 17):
column = columns[i]
if column == 'wind_speed':
continue
df[column] = df[column].astype('float64')
if len(df[df[column] == 0]) == len(df): # 全0
continue
mx = np.max(df[column])
mn = np.min(df[column])
df[column] = (df[column] - mn) / (mx - mn)
# print(df.isna().sum())
return df如何使用PyTorch搭建CNN实现风速预测




