
介绍 data =, pd.read_csv (& # 39; d:/test_data food_rank.csv& # 39;,编码=& # 39;use utf8 # 39;)
data.head ()
,,,name ,,全国矿工工会
0,,,,酥油茶,,,219.0
1,,,,青稞酒,,,95.0
2,,,,酸奶,,,62.0
3,,,,糌粑,,,16.0
4,,,,琵琶肉,,,2.0
,
#指定读取的列名
时间=data pd.read_csv (& # 39; d:/test_data food_rank.csv& # 39;, usecols=[& # 39;名字# 39;])
data.head ()
,,,的名字
0,,,,酥油茶
1,,,,青稞酒
2,,,,酸奶
3,,,,糌粑
4,,,,琵琶肉
,
#如果文件路径有中文,则需要知道参数引擎=& # 39;python # 39;
时间=data pd.read_csv (& # 39; d:/数据/food_rank.csv& # 39;,引擎=& # 39;python # 39;,编码=& # 39;use utf8 # 39;)
data.head ()
,,,name ,,全国矿工工会
0,,,,酥油茶,,,219.0
1,,,,青稞酒,,,95.0
2,,,,酸奶,,,62.0
3,,,,糌粑,,,16.0
4,,,,琵琶肉,,,2.0
#建议文件路径和文件名,不要出现中文 , * * * *系列:‘Series.to_csv \ (_path=None_ _index=True_ _sep=& # 39; _, _, _, _na \ _rep=& # 39; & # 39; _, _header=False_ _mode=& # 39; w # 39; _, _encoding=None_ \) #,,导入必要模块
import pandas as pd
得到sqlalchemy import create_engine
,
#初始化数据库连接
#用户名root 密码,,,端口,3306,,数据库,db2
时间=engine create_engine (& # 39; mysql + pymysql://根:@localhost: 3306/db2 # 39;)
#查询语句
时间=sql & # 39; & # 39; & # 39;
,,,select *,得到类;
& # 39;& # 39;& # 39;
#两个参数,,,sql语句,,数据库连接
时间=df pd.read_sql (sql,引擎)
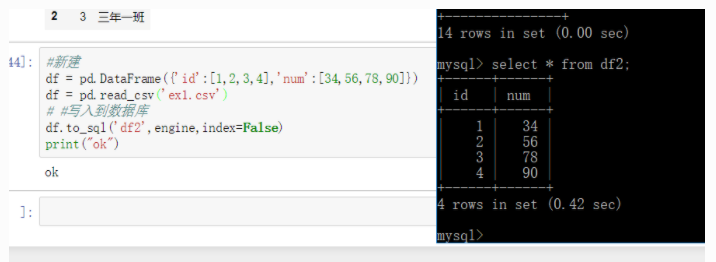
df #新建
时间=df pd.DataFrame ({& # 39; id # 39;: (1、2、3、4), & # 39; num # 39;:[34岁,56、78、90]})
时间=df pd.read_csv (& # 39; ex1.csv& # 39;)
#,#写入到数据库
df.to_sql (& # 39; df2& # 39;,引擎,指数=False)
印刷(“ok") Python主要用来做什么
这篇文章将为大家详细讲解有关如何在Python读取与存储数据,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
一、图示
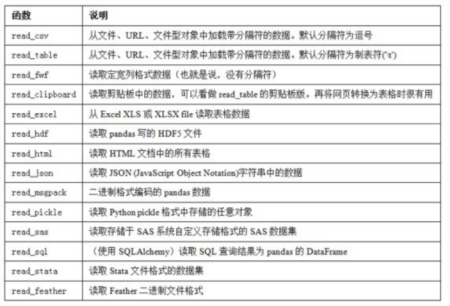

二、csv文件
1。读取csv文件read_csv (file_path或缓冲区、usecols编码):file_path:文件路径,usecols:指定读取的列名,编码:编码
2。写入csv文件
DataFrame: to_csv (file_path或缓冲区,sep、列头,指数,na_rep,模式):file_path:保存文件路径,默认没有,9月:分隔符,默认& # 39;,& # 39;列:是否保留某列数据,默认没有,头:是否保留列名,默认真,指数:是否保留行索引,默认真,na_rep:指定字符串来代替空值,默认是空字符,模式:默认& # 39;w # 39;,追加& # 39;一个# 39;
三,数据库交互熊猫
sqlalchemy pymysql

进入数据库查看:
Python主要应用于:1,网络开发;2、数据科学研究;3,网络爬虫;4、嵌入式应用开发,5日游戏开发;6桌面应用开发。
关于如何在Python读取与存储数据就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看的到。




