
介绍, C=pd.DataFrame({& # 39;一个# 39;:[& # 39;狗# 39;]* 3 +(& # 39;鱼# 39;)* 3 +(& # 39;狗# 39;],& # 39;b # 39;:[10、10、12、12、14日14日10]}) C.duplicated () C.drop_duplicates () , C.duplicated((& # 39;一个# 39;]),,,C.drop_duplicates((& # 39;一个# 39;])
,C.duplicated ([& # 39; b # 39;]),,, C.drop_duplicates ((& # 39; b # 39;]) <李>
这篇文章给大家介绍怎么在熊猫中使用DataFrame删除重复行,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
<强> 1。建立一个DataFrame

<强> 2。判断是否有重复项
用复制()函数判断,
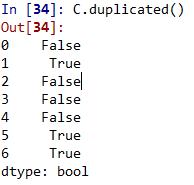
<强> 3只;有重复项,则可以用drop_duplicates()移除重复项
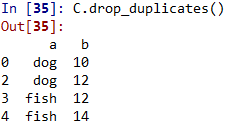
<强> 4只复制()和drop_duplicates()方法是以默认的方式判断全部的列(上面的例子中是看两个变量a和b是否都是重复出现)。
我们也可以对特定的列进行重复项判断。

<强> 5只;norepeat_df=df.drop_duplicates(子集=[& # 39;A_ID& # 39; & # 39; B_ID& # 39;],保持=& # 39;第一个# 39;)
#上面的命令去掉UNIT_ID和KPI_ID列中重复的行,并保留重复出现的行中第一次出现的行
补充:,
当保持=False时,就是去掉所有的重复行,
<李>当保持='第一个# 39;时,就是保留第一次出现的重复行,
<李>当保持=& # 39;这# 39;时就是保留最后一次出现的重复行只
关于怎么在熊猫中使用DataFrame删除重复行就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看的到。




