本文小编为大家详细介绍“怎么用Redis实现分布式锁”,内容详细,步骤清晰,细节处理妥当,希望这篇“怎么用Redis实现分布式锁”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。

单机上的锁和分布式锁的联系与区别
我们先来看下单机上的锁。
对于在单机上运行的多线程程序来说,锁本身可以用一个变量表示。
变量值为 0 时,表示没有线程获取锁;
变量值为 1 时,表示已经有线程获取到锁了。
我们通常说的线程调用加锁和释放锁的操作,实际上,一个线程调用加锁操作,其实就是检查锁变量值是否为 0。如果是 0,就把锁的变量值设置为 1,表示获取到锁,如果不是 0,就返回错误信息,表示加锁失败,已经有别的线程获取到锁了。而一个线程调用释放锁操作,其实就是将锁变量的值置为 0,以便其它线程可以来获取锁。
我用一段代码来展示下加锁和释放锁的操作,其中,lock 为锁变量。
acquire_lock(){
if lock == 0
lock = 1
return 1
else
return 0
}
release_lock(){
lock = 0
return 1
}和单机上的锁类似,分布式锁同样可以用一个变量来实现。客户端加锁和释放锁的操作逻辑,也和单机上的加锁和释放锁操作逻辑一致:加锁时同样需要判断锁变量的值,根据锁变量值来判断能否加锁成功;释放锁时需要把锁变量值设置为 0,表明客户端不再持有锁。
但是,和线程在单机上操作锁不同的是,在分布式场景下,锁变量需要由一个共享存储系统来维护,只有这样,多个客户端才可以通过访问共享存储系统来访问锁变量。相应的,加锁和释放锁的操作就变成了读取、判断和设置共享存储系统中的锁变量值。
这样一来,我们就可以得出实现分布式锁的两个要求。
要求一:分布式锁的加锁和释放锁的过程,涉及多个操作。所以,在实现分布式锁时,我们需要保证这些锁操作的原子性;
要求二:共享存储系统保存了锁变量,如果共享存储系统发生故障或宕机,那么客户端也就无法进行锁操作了。在实现分布式锁时,我们需要考虑保证共享存储系统的可靠性,进而保证锁的可靠性。
好了,知道了具体的要求,接下来,我们就来学习下 Redis 是怎么实现分布式锁的。
其实,我们既可以基于单个 Redis 节点来实现,也可以使用多个 Redis 节点实现。在这两种情况下,锁的可靠性是不一样的。我们先来看基于单个 Redis 节点的实现方法。
基于单个 Redis 节点实现分布式锁
作为分布式锁实现过程中的共享存储系统,Redis 可以使用键值对来保存锁变量,再接收和处理不同客户端发送的加锁和释放锁的操作请求。那么,键值对的键和值具体是怎么定的呢?
我们要赋予锁变量一个变量名,把这个变量名作为键值对的键,而锁变量的值,则是键值对的值,这样一来,Redis 就能保存锁变量了,客户端也就可以通过 Redis 的命令操作来实现锁操作。
为了帮助你理解,我画了一张图片,它展示 Redis 使用键值对保存锁变量,以及两个客户端同时请求加锁的操作过程。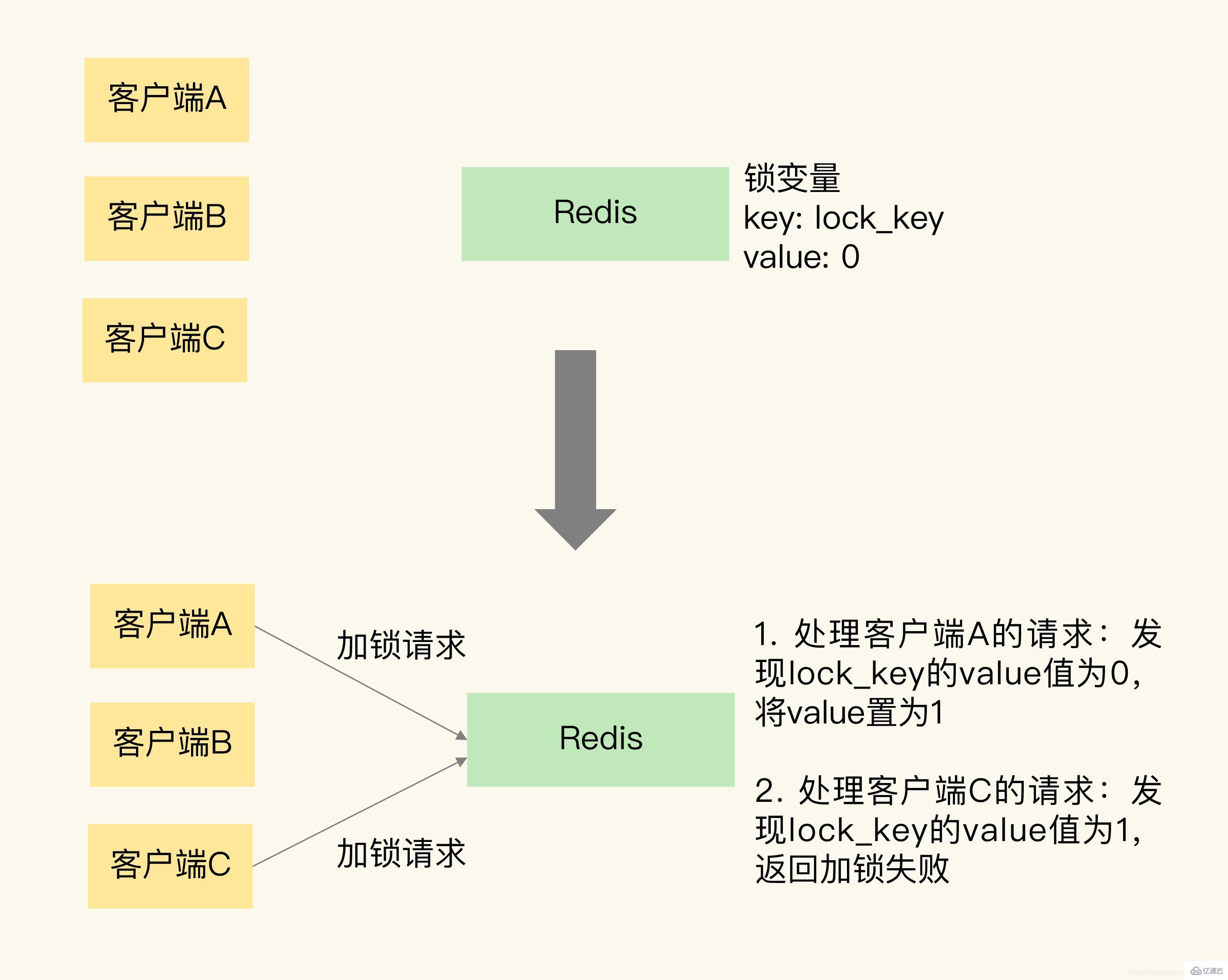
可以看到,Redis 可以使用一个键值对 lock_key:0 来保存锁变量,其中,键是 lock_key,也是锁变量的名称,锁变量的初始值是 0。
我们再来分析下加锁操作。
在图中,客户端 A 和 C 同时请求加锁。因为 Redis 使用单线程处理请求,所以,即使客户端 A 和 C 同时把加锁请求发给了 Redis,Redis 也会串行处理它们的请求。
我们假设 Redis 先处理客户端 A 的请求,读取 lock_key 的值,发现 lock_key 为 0,所以,Redis 就把 lock_key 的 value 置为 1,表示已经加锁了。紧接着,Redis 处理客户端 C 的请求,此时,Redis 会发现 lock_key 的值已经为 1 了,所以就返回加锁失败的信息。
刚刚说的是加锁的操作,那释放锁该怎么操作呢?其实,释放锁就是直接把锁变量值设置为 0。