
从Zeppelin:一个分布式KV存储平台之概述的介绍中我们知道元信息节点Meta以集群的形式向整个Zeppelin提供元信息的维护和提供服务。可以说Meta集群是Zeppelin的大脑,是所有元信息变化的发起者。每个Meta节点包含一个Floyd实例,从而也是Floyd的一个节点,Meta集群依赖Floyd提供一致性的内容读写。本文将从角色、线程模型、数据结构、选主与分布式锁、集群扩容缩容及成员变化几个方面详细介绍,最后总结在Meta节点的设计开发过程中带来的启发。
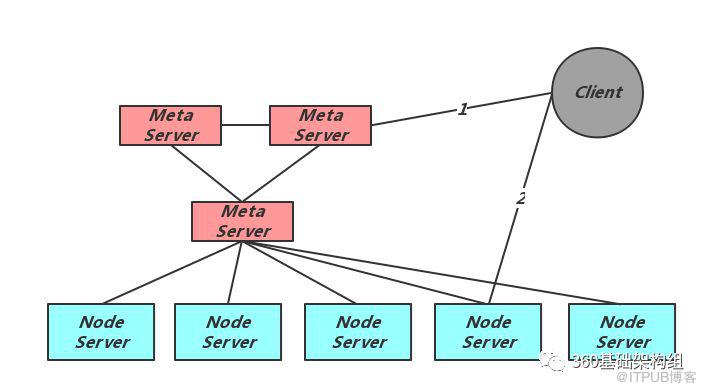
从上图可以看出Meta集群的中心地位:
向Client及Node Server提供当前的元信息,包括分片副本信息,Meta集群成员信息等;
保持与Node Server的心跳检测,发现异常时进行切主;
接受并执行运维命令,完成相应的元信息变化,包括扩容、缩容、创建Table、删除Table等;
线程模型
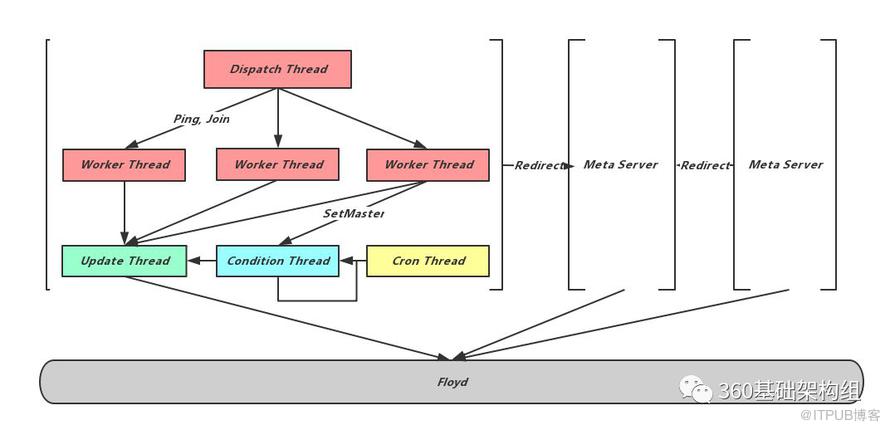
相对于存储节点,元信息节点的线程模型比较简单:
处理请求的Dispatch线程和Worker线程;
修改Floyd的Update线程,Update线程是唯一的Floyd修改者。所有的元信息修改需求都会通过任务队列转交给Update线程。同时为了减轻Floyd的写入压力,这里采用了延时批量提交的方式;
Condition线程用来等待Offset条件,一些元信息修改操作如SetMaster,扩容及缩容,需要等到分片副本的主从Binlog Offset追齐时才能执行,Meta从与Node之间的心跳中得到Offset信息,Condition线程不断的检查主从的Offset差距,仅当追齐时通知Update线程完成对应修改;
Cron线程执行定时任务,包括检查和完成Meta主从切换、检查Node存活、Follower Meta加载当前元信息、执行数据迁移任务等。
为了完成上述任务,Meta节点需要维护一套完整的数据,包括Node节点心跳信息、Node节点Offset信息、分片信息、Meta成员信息、扩容迁移信息等。由于一致性算法本身限制,我们需要尽量降低对Floyd的访问压力,因此并不是所有这些数据都需要直接维护在Floyd中。Zeppelin根据数据的重要程度、访问频率及是否可恢复进行划分,仅仅将低频访问且不易恢复的数据记录在Floyd中。
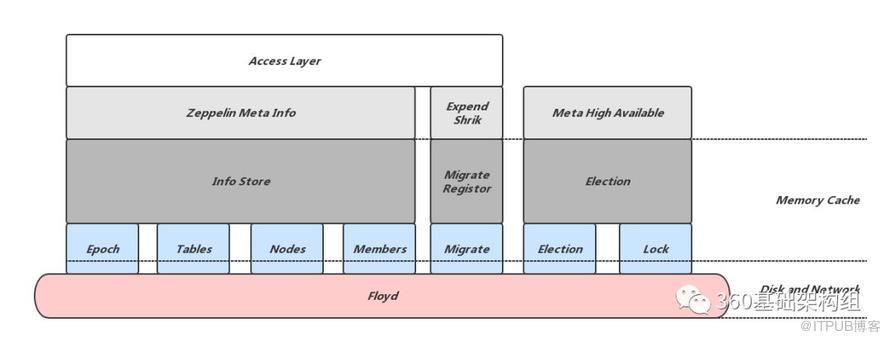
上图所示是Meta节点所维护数据的数据结构及存储方式,可以看出,除了一致性库Floyd中记录的数据外,Meta还会在内存中维护对应的数据结构,内存数据结构依赖Floyd中的数据,重新组织并提供更方便访问的接口。从所完成的任务来看,主要包括三个部分:
对应内存数据结构InfoStore,InfoStore依赖Floyd中的数据,包括:
当前元信息的版本号Epoch,每次元信息的变化都会对Epoch加一;
数据分片副本的分布及主从信息Tables;
存储节点地址及存活信息Nodes;
Meta集群自己的成员信息Members;
InfoStore重新组织这些数据,对外提供方便的查询和修改接口;除此之外InfoStore还会维护一些频繁修改但可以恢复的数据:
存储节点上次心跳时间:宕机后丢失,可以通过Floyd中的Nodes信息及恢复时的当前时间恢复,注意这里使用恢复时的当前时间相当于延长的存储节点的存活;
存储节点的分片Binlog偏移信息:Meta需要这些信息来决定副本的主从切换,宕机恢复后可以从Node的心跳中获得,这也就要求Node在重新建立心跳连接后的第一个包需要携带全量的Binlog偏移信息。
对应内存数据结构MigrateRegister,负责迁移过程的注册和提供,这部分内容将在稍后的集群扩容、缩容章节中详细介绍。
Meta以集群的方式提供服务,Leader节点完成写操作,Follower分担读压力,节点之间依赖Floyd保证一致,从而实现Meta集群的高可用。内存数据结构Election负责节点异常时的选主,依赖Floyd提供的Lock接口及其中的Election相关数据。这部分内容将在稍后的选主与分布式锁章节中详细介绍。




