<前>
——添加分析实际执行来获得执行计划,可不加
explain analyze select *,得到test_table;
——只看执行路径,不看成本
explain (costs 假),select *,得到test_table;
——通过实际执行来看代价和缓冲区命中情况
explain (analyze 的确,buffers true), select *,得到test_table;
——与执行计划相关的配置项
enable_seqscan:是否选择全表扫描
enable_indexscan:是否选择索引扫描
enable_bitmapscan:是否选择位图扫描
enable_tidscan:是否tid扫描(类似oracle rowid)
enable_nestloop:多表连接时,是否选择嵌套循环连接
enable_hashjoin:多表连接时,是否选择哈希连接
enable_mergejoin:多表连接时,是否选择合并连接
enable_hashagg:多表连接时,是否使用散列聚合
enable_sort:是否使用明确的排序。
——成本基准值参数
seq_page_cost:执行计划中一次顺序访问一个数据块页面的开销,默认1.0
random_page_cost:随机访问一个数据块页面的开销,默认4.0
cpu_tuple_cost:执行计划中,处理一条数据行的开销,默认0.01
cpu_idex_tuple_cost:处理一条索引行的开销,默认0.005
cpu_operator_cost:执行一个操作符或函数的开销,默认0.0025
effective_cache_size:执行计划中在一次索引扫描中可用的磁盘缓冲区的有效大小。默认128 mb
——基因查询优化:是一个使用探索式搜索来执行查询规划的算法,可以降低负载查询的规划时间,它的检索是随机的。
geqo:允许和禁止基因查询优化
geqo_threshold:只当涉及的从关系数量至少有这么多个时,才使用基因查询优化。
geqo_effort:控制geqo里规划时间和查询规划有效性直接的平衡。默认5 - 10页
geqo_pool_size:控制geqo使用池的大小
geqo_generations:控制geqo使用的子代数目,子代意思算法的迭代次数
geqo_selection_bias:控制geqo使用的选择性偏好
geqo_seed:控制geqo使用的随机数产生器的初始值,用以选择随机路径。
——统计信息收集
——控制是否输出sql执行过程的统计信息到日志
log_statment_stats
log_parser_stats
log_planner_stats
log_executor_stats
——收到收集统计信息
analyze test01 (id2);
analyze test01 (id1, id2);
analyze test01;
——设置收集统计信息行数
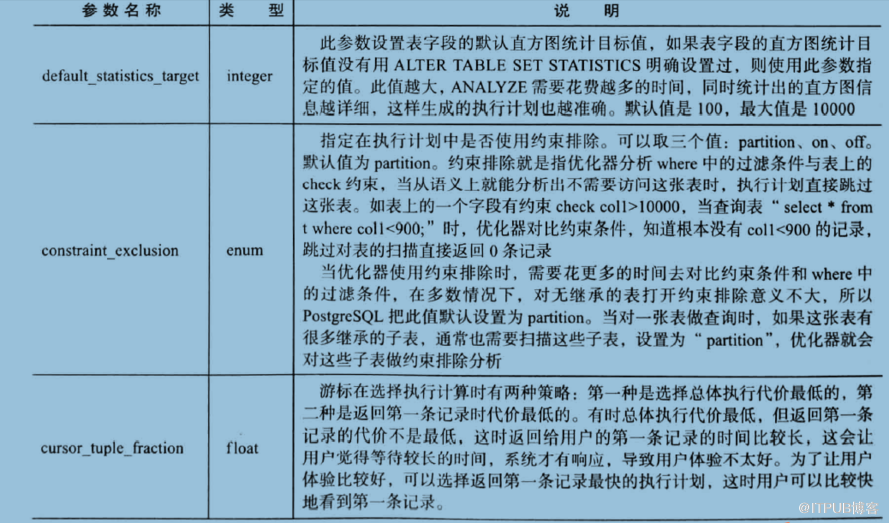
set default_statistics_target 用500;
analyze test01;
——一、设置表中每个列的统计值的目标
alter table test01 alter column id2 set statistics 200;
——指定这个列上有多少唯一值
alter table test01 alter column id2 set (n_distinct=2000);
——子表会继续使用父表的设计
alter table test01 alter column id2 set (n_distinct_inherited=2000);
之前