
过去的一年多的时间中,大部分的工作都围绕着Zeppelin这个项目展开,经历了Zeppelin的从无到有,再到逐步完善稳定。见证了Zeppelin的成长的同时,Zeppelin也见证了我的积累进步。对我而言,Zeppelin就像是孩提时代一同长大的朋友,在无数次的游戏和谈话中,交换对未知世界的感知,碰撞对未来的憧憬,然后刻画出更好的彼此。这篇博客中就向大家介绍下我的这位老朋友。
定位
Zeppelin是一个分布式的KV存储平台,在设计之初,我们对他有如下几个主要期许:
高性能;
大集群,因此需要有更好的可扩展性和必要的业务隔离及配额;
作为支撑平台,向上支撑更丰富的协议;
Zeppelin的整个设计和实现都围绕这三个目标努力,本文将从API、数据分布、元信息管理、一致性、副本策略、数据存储、故障检测几个方面来分别介绍。
为了让读者对Zeppelin有个整体印象,先介绍下其提供的接口:
基本的KV存储相关接口:Set、Get、Delete;
支持TTL;
HashTag及针对同一HashTag的Batch操作,Batch保证原子,这一支持主要是为了支撑上层更丰富的协议。
最为一个分布式存储,首要需要解决的就是数据分布的问题。另一篇博客浅谈分布式存储系统数据分布方法中介绍了可能的数据分布方案,Zeppelin选择了比较灵活的分片的方式,如下图所示:
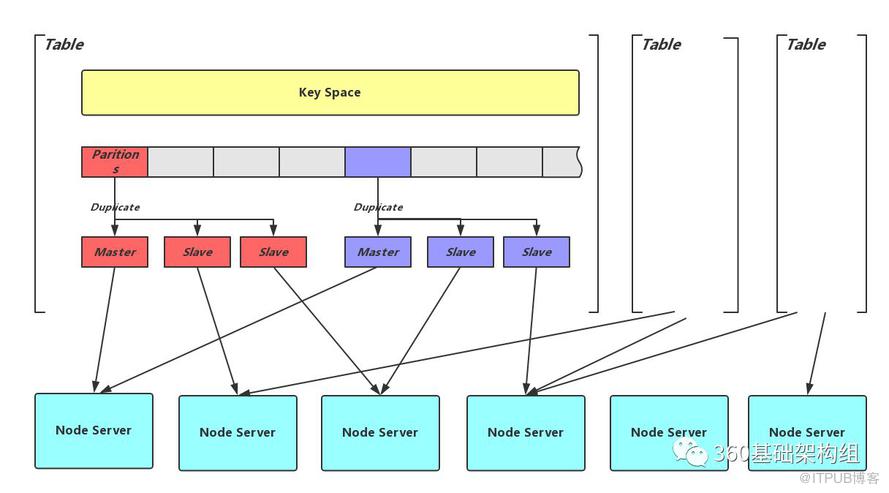
用逻辑概念Table区分业务,并将Table的整个Key Space划分为相同大小的分片(Partition),每个分片的多副本分别存储在不同的存储节点(Node Server)上,因而,每个Node Server都会承载多个Partition的不同副本。Partition个数在Table创建时确定,更多的Partition数会带来更好的数据均衡效果,提供扩展到更大集群的可能,但也会带来元信息膨胀的压力。实现上,Partition又是数据备份、数据迁移、数据同步的最小单位,因此更多的Partition可能带来更多的资源压力。Zeppelin的设计实现上也会尽量降低这种影响。
可以看出,分片的方式将数据分布问题拆分为两层隐射:从Key到Partition的映射可以简单的用Hash实现。而Partition副本到存储节点的映射相对比较复杂,需要考虑稳定性、均衡性、节点异构及故障域隔离(更多讨论见浅谈分布式存储系统数据分布方法)。关于这一层映射,Zeppelin的实现参考了CRUSH对副本故障域的层级维护方式,但摈弃了CRUSH对降低元信息量稍显偏执的追求。
在进行创建Table、扩容、缩容等集群变化的操作时,用户需要提供整个:
集群分层部署的拓扑信息(包含节点的机架、机器等部署信息);
存储节点权重;
各个故障层级的分布规则;
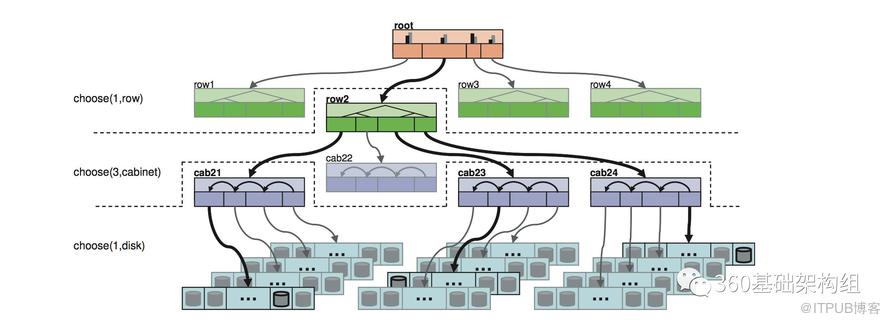
Zeppelin根据这些信息及当前的数据分布直接计算出完整的目标数据分布,这个过程会尽量保证数据均衡及需要的副本故障域。下图举例展示了,副本在机架(cabinet)级别隔离的规则及分布方式。更详细的介绍见Decentralized Placement of Replicated Data
上面确定了分片的数据分布方式,可以看出,包括各个分片副本的分布情况在内的元信息需要在整个集群间共享,并且在变化时及时扩散,这就涉及到了元信息管理的问题,通常有两种方式:
有中心的元信息管理:由中心节点来负责整个集群元信息的检测、更新和维护,这种方式的优点是设计简洁清晰,容易实现,且元信息传播总量相对较小并且及时。最大的缺点就是中心节点的单点故障。以BigTable和Ceph为代表。
对等的元信息管理:将集群元信息的处理负担分散到集群的所有节点上去,节点间地位一致。元信息变动时需要采用Gossip等协议来传播,限制了集群规模。而无单点故障和较好的水平扩展能力是它的主要优点。Dynamo和Redis Cluster采用的是这种方式。
考虑到对大集群目标的需求,Zeppelin采用了有中心节点的元信息管理方式。其整体结构如下图所示:
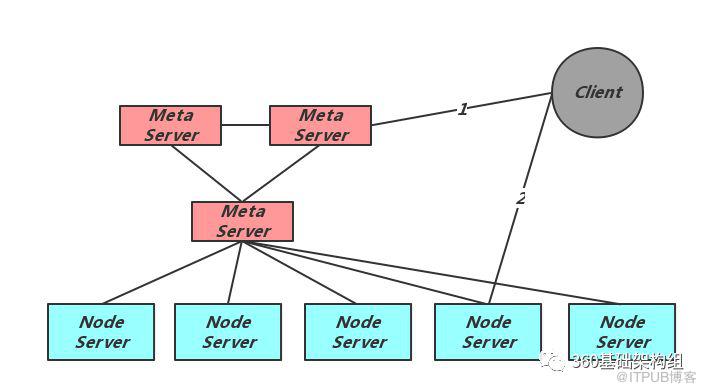
可以看出Zeppelin有三个主要的角色,元信息节点Meta Server、存储节点Node Server及Client。Meta负责元信息的维护、Node的存活检测及元信息分发;Node负责实际的数据存储;Client的首次访问需要先从Meta获得当前集群的完整数据分布信息,对每个用户请求计算正确的Node位置,并发起直接请求。




