
一条俊俏的SQL被一个懵懂的少年,扔向了深远的TCP隧道,少年苦苦等待,却迟迟等不来那满载而归。于是少年气愤,费尽苦心从度娘那边求来的一手好代码,等来的却是超时…
如果你也正在经历着这些苦涩的等待,那么该了解执行计划了,如果你自认为执行计划已经了如指掌,那么你该读一读SQL Server 2017新特性,适应性查询处理,我蹩脚的将其翻译为“自适应查询处理”。
在讲解概念之前,首先要对内存分配要有清晰的理解。一个查询请求在执行完毕之后,会有详细的内存分配指标和统计值附加在它的执行计划属性上。这些内存分配指标和统计值,分别是执行前预估的内存分配和最佳内存大小以及运行中被分配的内存大小。
如果一开始内存预估分配不准确,在执行的时候,就会分配不到合理的执行内存,导致整个查询期间,频繁的往下边里面去做泄漏(这个词真不好翻译,有缓存溢出的意思,即内存装不下,暂交给tempdb存储的意思),将不能被当前内存空间容纳的数据缓存到下边里面,利用硬盘IO来缓存数据,比起内存存储效率差了很多。因此在执行前就需要保证预估的数据量大小和需要的内存比较精确。这里需要对统计信息(统计)做实时更新,以便预分配内存准确。
Brentozar有个实例可以很好的解释和解决这个问题:
https://www.brentozar.com/blitzcache/tempdb-spills/
换句话来说,对即将执行的查询,分配足够多的内存,那么该查询的执行所需的数据,就完全可以在内存中处理,而不会溢出到硬盘,从而查询速度就快。
如果发生泄漏会有系统提示,这必须依靠执行计划才能铺捉到
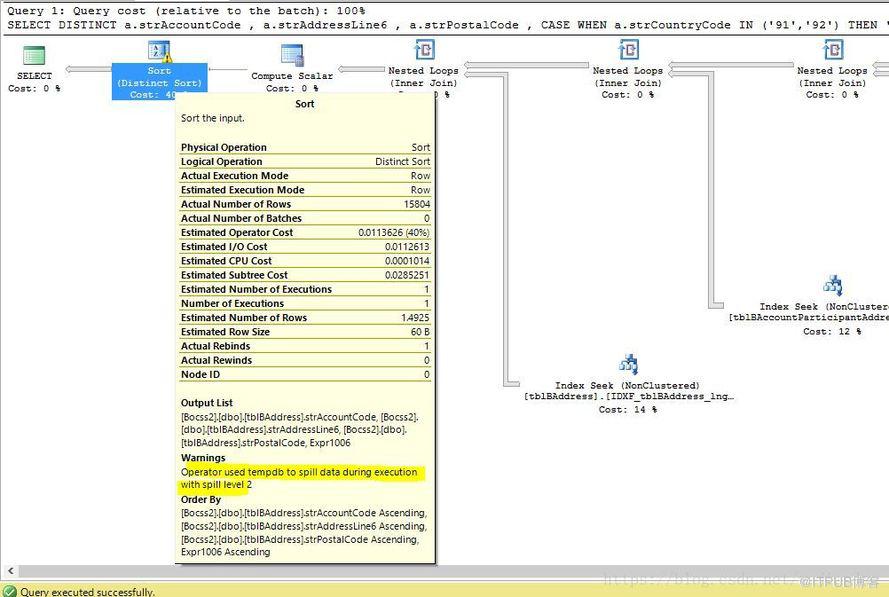
在SQL Server 2017出来之前,需要掌握DBA知识才能意识和掌握处理这类事情。但SQL Server 2017之后,作为普通的一名开发者,完全可以忽略这类问题,因为自适应查询处理已经帮我们在幕后优化这类SQL。
如上所说,SQL执行完毕之后,会将执行计划与执行环境(执行上下文)一起缓存.Adaptive查询处理引入了批处理模式内存格兰特
只提供反馈;执行引擎通过对执行计划缓存属性的校验,可以发现请求的执行过程中,是否发生了泄漏,对于发生泄漏的情况,引擎会对这份执行计划做重估,一旦发现如统计信息过期等导致的泄漏,就会用最新的统计信息去重估执行计划,更新执行计划中分配内存的策略,要么降低内存分配提高并发中内存需要,要么提高内存,减少泄漏的发生概率。这些校验都回反馈给记忆给予反馈,由它采用最新的策略,去更新执行计划缓存。
上述讲的是自适应查询处理(自适应查询处理)中批处理模式记忆给予反馈的一个自动处理特性,被称为记忆给予反馈分级。除此之外,SQL Server 2017还带来了更多的智能优化策略,自动化完成DBA的部分工作。




