Python的优点有哪些 1,简单易用,与C/c++、Java、c#等传统语言相比,Python对代码格式的要求没有那么严格;2,Python属于开源的,所有人都可以看到源代码,并且可以被移植在许多平台上使用;3,Python面向对象,能够支持面向过程编程,也支持面向对象编程;4,Python是一种解释性语言,Python写的程序不需要编译成二进制代码,可以直接从源代码运行程序;5,Python功能强大,拥有的模块众多,基本能够实现所有的常见功能。
<强>前言
最近在学习Python爬虫方面的知识,网上有一博客专栏专门写爬虫方面的,看到用urllib请求有道翻译接口获取翻译结果。发现接口变化很大,用md5加了密,于是自己开始破解。加上网上的其他文章找源码方式并不是通用的,所有重新写一篇记录下。
<强>爬取条件
要实现爬取的目标,首先要知道它的地址,请求参数,请求头,响应结果。
<强>进行抓包分析
打开有道翻译的链接:http://fanyi.youdao.com/H缓笤诎磃12点击网络项。这时候就来到了网络监听窗口,在这个页面中发送的所有网络请求,都会在网络这个地方显示出来,如果是空白的,点击XHR。接着我们在翻译的窗口输入我们需要翻译的文字,比如输入地狱。然后点击自动翻译按钮,那么接下来在下面就可以看到浏览器给有道发送的请求,这里截个图看看:

点击链接,就可以看到整个请求的信息。包括请求头,请求参数,响应结果。
这里面有一个问题就是参数进行了加密。我们需要知道这些参数是如何加密的。
<强>破解加密难题
要想知道如何加密的,需要查看源码。于是我们需要知道发起这个请求的js文件。在文件查找这个相关代码。刚才我们监听了网络请求,可以看到发起请求的js文件。那么接下来查找发起请求的链路,鼠标浮到请求文件上,显示了一系列执行方法,我们点击跟业务相关的那个方法对应的文件链接,这里是t。翻译对应的连接。
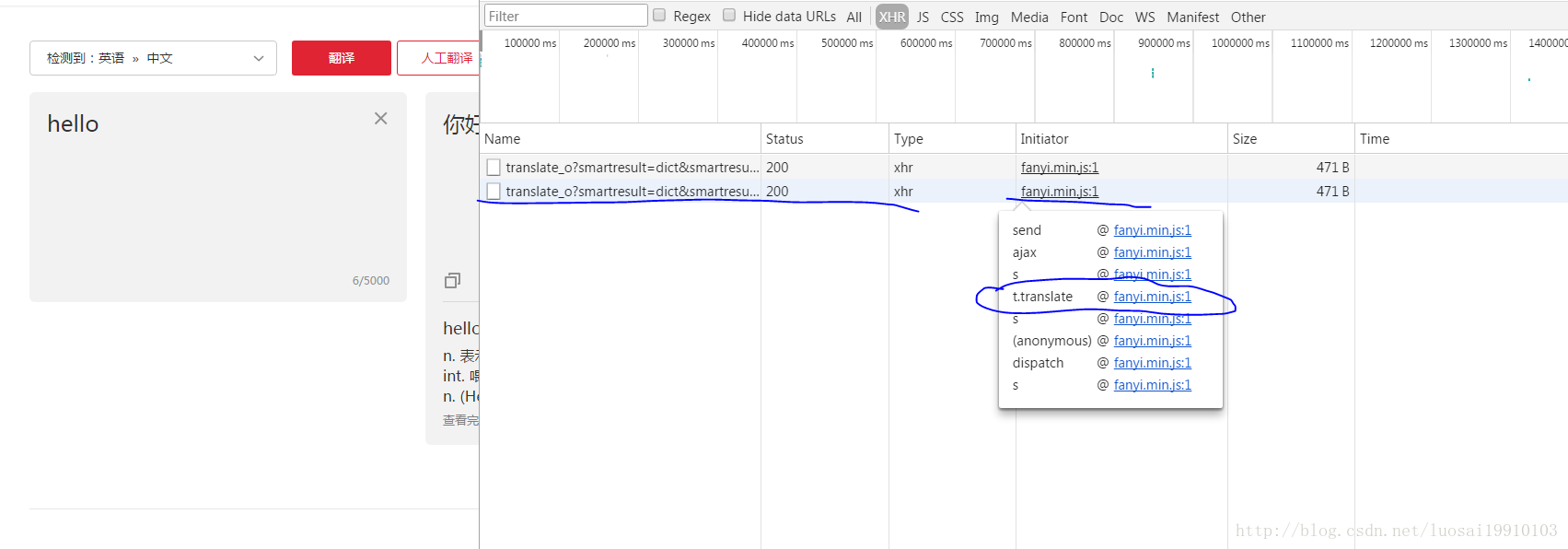
点击进入查看对应的源码
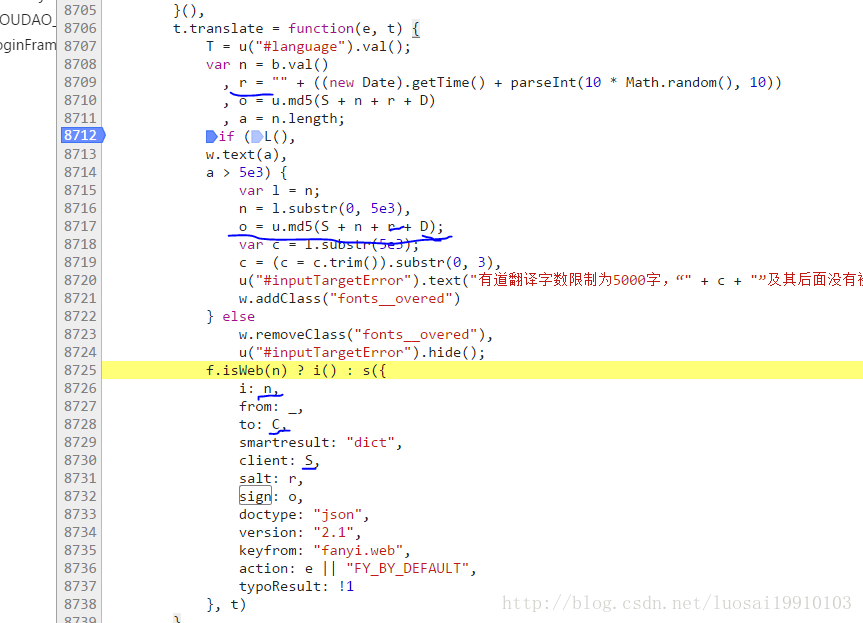
我们可以看到我,盐,标志是变量,其他的请求参数是常量。我是需要翻译的字符串,盐是时间戳生成的13位,标志是S + n + r + D
也就年代是客户机的值,也就是fanyideskweb。我们查找D这个常量,在底栏输入框输入D=(空格维空格=空格;格式化后的代码规范)点击右边的Aa让搜索时大小写敏感。回车查找到下一个,直到找到对应的值。
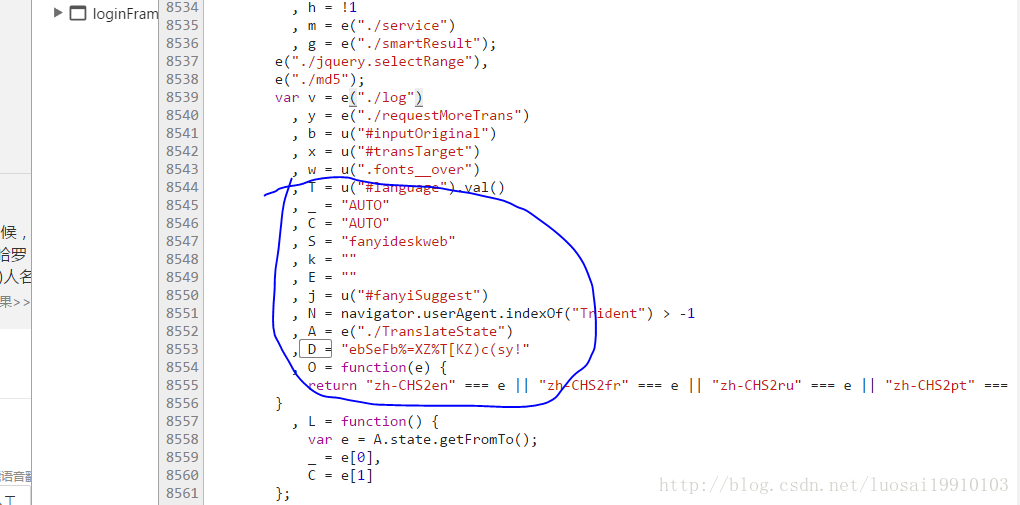
在上图我们看到了_,C、S、D等常量。
于是你以为构建一个请求,传好这些参数就好了。别忘了,为了反爬虫,都是会校验请求头。于是要模拟浏览器的请求头。经过验证只需要用户代理,推荐人,饼干三个请求头。
实现代码:
#, - *安康;编码:utf-8 - * -
得到urllib import 请求,解析
import json
import 时间
得到hashlib import md5
& # 39;& # 39;& # 39;
def dicToSortedStrParam (dic={}):
keyList 才能=,排序(dic)
str 才能=?“
for 才能;我key 拷贝列举(keyList):
,,,if 我==len (keyList) 1:
,,,,,str +=, key +“=?,迪拜国际资本(例子)
,,,:
,,,,,str +=, key +“=?,迪拜国际资本(例子),+,“,“
,才能通过
return 才能,str
& # 39;& # 39;& # 39;
def create_md5(数据):
md5_obj 才能=,md5 ()
md5_obj.update才能(data.encode (“utf-8"))
return 才能;md5_obj.hexdigest ()
if __name__ ==,“__main__":
request_url =,才能“http://fanyi.youdao.com/translate_o?smartresult=dict& smartresult=rule"
translate =,才能“hell"
c =,才能“fanyideskweb"
data 才能=,{}
数据才能(“我”),=,翻译
数据才能[“from"],=,“AUTO"
数据才能[“to"],=,“AUTO"
数据才能[“smartresult"],=,“dict"
数据才能[“client"], c=,
数据才能[“doctype"],=,“json"
数据才能[“version"],=,“2.1”;
数据才能[“keyfrom"],=,“fanyi.web"
数据才能[“action"],=,“FY_BY_REALTIME"
数据才能[“typoResult"],=,“false"
salt 才能=,str (int(圆(time.time (), 3) * 1000))
#,才能加密
数据才能[“salt"],=,盐
#,才能a =,“rY0D ^ 0 & # 39; nM0} g5Mm1z % 1 g4",,网上别人的,也可以
a =,才能“ebSeFb %=XZ % T [KZ) c (sy !“
时间=sign 才能;create_md5 (c + +盐+翻译)
数据才能[“sign"],=,标志
headers 才能=,{}
头才能[“User-Agent"],=,“Mozilla/5.0, (Windows NT 10.0;, Win64;, x64), AppleWebKit/537.36, (KHTML, like 壁虎),Chrome/63.0.3239.132 Safari/537.36“
#才能,标题(“Content-Type"),=,“应用程序/x-www-form-urlencoded;, charset=UTF-8"
头才能[“Referer"],=,“http://fanyi.youdao.com/"
#才能,标题(“Host"),=,“fanyi.youdao.com"
#才能,标题(“Origin")=癶ttp://fanyi.youdao.com"
头才能[“Cookie"]=癘UTFOX_SEARCH_USER_ID=-948455480 @10.169.0.83;,“\
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null





