
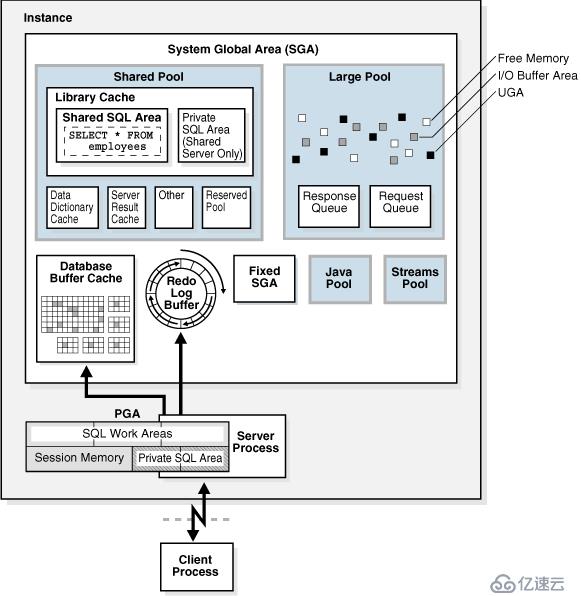
,甲骨文数据库包含了如下基本内存组件
系统全局区(SGA)
SGA是一组共享内存结构,as ,包含数据和控制信息>服务器process 和后台进程。收集个人pga,或是平平。数据库初始化参数设置实例PGA的大小,不是个人PGA。李李
<>用户全球区域(佐治亚大学)
佐治亚大学是内存关联到一个用户会话。李李
<>
软件代码领域软件代码区域部分的内存用来存储正在运行或运行的代码。Oracle数据库代码存储在软件领域,通常是在一个不同的位置从用户程序更多的独家或保护位置。
内存管理
甲骨文依赖于内存相关的初始化参数来控制内存的管理。
内存管理有如下三个选项
自动内存管理
你指定目标大小例如内存。数据库实例自动调到目标内存大小,根据需要重新分配内存PGA SGA和实例。李李
<>自动共享内存管理
这个管理模式部分自动化。你设定了一个目标大小的SGA,然后选择设置一个总目标大小的PGA或管理PGA单独工作区域。李李
<>
人工管理内存,而不是设置的总内存大小,设置许多SGA和实例的初始化参数管理组件单独PGA。
佐治亚大学概览
佐治亚大学是会话内存,用来保存会话变量例如登录信息,已经数据库会话需要的其他信息。
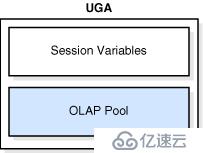
当PL/SQL包加载进内存时,佐治亚大学中包含了,也就是调用PL/SQL时指定的变量值。
PGA概览
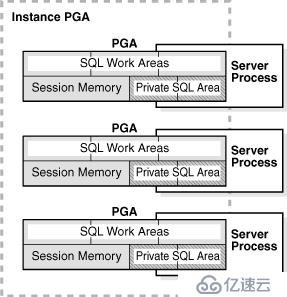
PGA缓冲区,则主要是为了某个用户进程所服务的。这个内存区不是共享的,只有这个用户的服务进程本身才能够访问它自己的PGA区。做个形象的比喻,SGA就好像是操作系统上的一个共享文件夹,不同用户可以以此为平台进行数据方面的交流。而PGA就好像是操作系统上的一个私有文件夹,只有这个文件夹的所有者才能够进行访问,其他用户都不能够访问。虽然程序缓存区不向其他用户的进程开放,但是这个内存区仍然肩负着一些重要的使命,如数据排序,权限控制等等都离不开这个内存区。
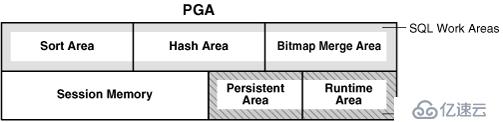
PGA组件
数据库缓冲区缓存
<李>重做日志缓冲区
<李>共享池<李>
大池<李>
Java池<李>
流池固定SGA <李>
缓冲区缓存
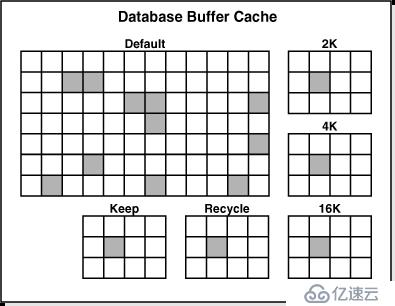
缓冲区缓存按照类型分为3个池
默认池这池的位置通常缓存块。除非你手动配置不同的缓冲池中,默认池alt=凹坠俏难爸阅苡呕?十四)内存">
首先甲骨文以每个数据块的文件号,块号,类型做散列运算,得到哈希值。
对于哈希值相同的块,放在一个散列桶中。
因为缓冲区的大小毕竟有限,缓冲区中的数据块需要根据一定的规则提出内存。
甲骨文采用了LRU算法维护一个LRU链表,来决定哪些数据块被淘汰。
通用的淘汰算法如下
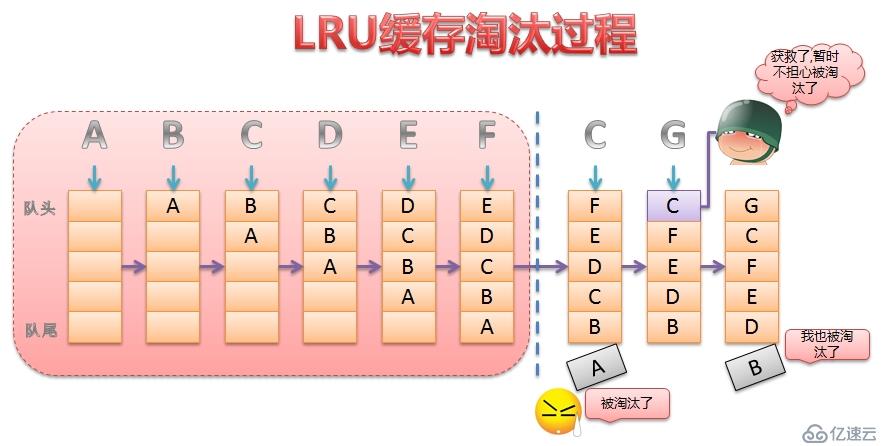
甲骨文改进了LRU算法,引入了联系数概念,以及LRU链表分为热端头和冷端头。
联系数:
,用来记录数据块访问的频繁度,此数值在内存中不受保护,多个进程可以同时修改它。这个值并不是精准的表示块被访问的次数,只是一种趋势。3秒内无论多少用户,访问多少次块。此值加1。null




