
,当向甲骨文提交一个sql命令时,Oracle到底做了哪些事情?对这个问题有很好的理解,能帮助你更好的分析sql语句的优化。
,执行一条sql语句从开始到结束,需要经历4个步骤:
分析,对提交的语句进行语法分析,语义分析和共享池检查。
<李>优化——生成一个可在数据库中用来执行语句的最佳计划
<李>行资源生成——为会话取得最佳计划并建立执行计划
<李>语句执行,完成实际执行查询的行资源生成步骤的输出。对应DDL来说,这一步就是语句的结,束。对应选择来说,这一步是取数据的开始。
,以上步骤,有的是可以省略的,例如优化,行资源生成器阶段。这样可以节省大量的时间。
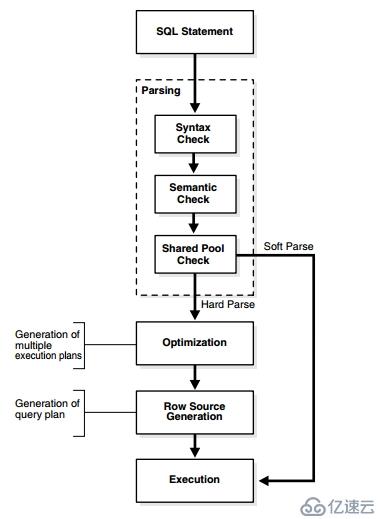
一、分析:
,语法分析,sql是否符合语法标准。
,语义分析,假设sql是合法的,但是它有意义吗?你要访问的对象,你有访问权限吗?查询的列存在吗?是否存在歧义等待。
,对于DML语句,还有第三步。
,共享池检查,此语句是否被其他用户使用过?可以重用已经执行过的工作吗?如果是,就是软解析软解析,如果否,那就是硬解析。
,DDL总是硬解析,语句从不重用。
,共享池是SGA中的一部分,用来缓存以前执行过的sql语句,PLSQL,数据字典内容的缓存(以行的形式缓存内容,而缓冲区缓存是以块的方式缓存内容)以及其他许多信息,以供会话重用。
,从技术上来说,甲骨文的语句解析分为两种:
硬解析——语句通过语句执行的每一个步骤从分析到优化,到行资源生成,到语句执行。
<李>软解析——语句通过语句执行的某些步骤,特别是跳过优化步骤(最昂贵的步骤)。为了执行软解析,必须通过两个步骤。首先甲骨文必须进行语义匹配,查看提交给甲骨文的语句是否已经被执行过,然后,进行环境匹配。比如一个会话的初始化参数optimizer_mode=ALL_ROWS,一个会话的初始化参数optimizer_mode=FIRST_ROWS,这两个会话的环境就不一样。
,
,为了开始这个处理,甲骨文必须在共享池中寻找语句。为了高效的完成此操作,Oracle将每个提交的sql语句,进行哈希算法,生成一个hash_values.oracle使用hash_values查找共享池中是否有相同的语句。
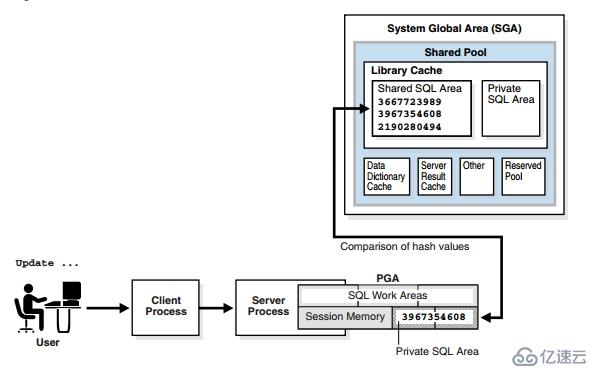
,一旦找到,甲骨文将进行语义和环境检查,sql语句都相同,难道还有语义不同的吗?我们看下面的例子。
建立两个用户,
2。赋予用户权限
3。启用一个会话
4。启用另一个会话




