MongoDB复制集部署和基本管理
MongoDB复制集概述
复制集(副本集)是额外的数据副本,是跨多个服务器同步数据的过程,复制集提供了冗余并增加了数据的可用性,通过复制集可以对硬件故障和中断服务进行恢复。
复制集由下列优点:
-
<李>让数据更安全李
<李>高数据可用性(7 * 24)
<李>灾难恢复李
<李>无停机维护(如备份,索引重建,故障转移)
<李>读缩放(额外的副本读取)
<李>副本集对应用程序是透明的
复制集工作原理
MongoDB的复制集至少需要两个节点。其中一个节点是主节点(主要),负责处理客户端的请求,其余的都是从节点(Serondary),负责复制主节点上的数据。
MongoDB各个节点常见的搭配方式为:一主一从或者一主多从的。主节点记录所有打操作到oplog中,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。如下图所示:
客户端在主节点写入数据,在主节点写入数据,主节点与从节点进行数据交互保证数据的一致性。如果其中一个节点出现故障,其他节点马上会将业务接过来,无需停机操作。
MongoDB复制集部署
配置多个实例
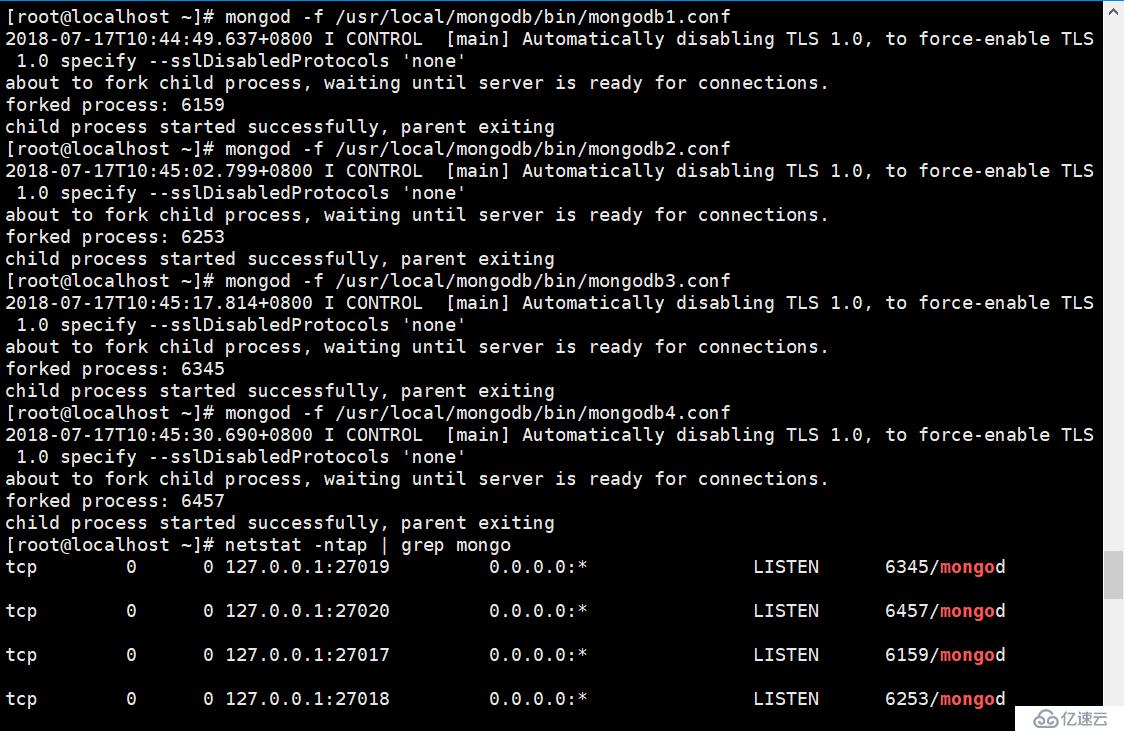
在上一篇的博客中已经讲解了MongoDB开启多实例的方法,这里就不多赘述,我们用相同的方法创建了四个MongoDB实例。在启动四个实例前,先要修改每个实例的配置文件,配置replSet参数值都为同一个值,这个值作为复制集的名称,具体操作如下:
<代码> root@localhost ~ # vim/usr/local/mongodb/bin/mongodb1.conf 端口=27017 dbpath=/数据/mongodb1 logpath=/数据/日志/mongodb/mongodb1.log logappend=true 叉=true maxConns=5000 replSet=kgcrs #配置复制集的名称
在其他的三个实例的配置文件中最后一行,加上相同的一句代码就行。开启四个实例进程。
<代码> [root@localhost ~]=$ #出口路径路径:/usr/地方/mongodb/bin/#由于之前重启过,重新设置环境变量 # mongod - f/usr/local/mongodb/bin/mongodb1.conf root@localhost ~ #开启端口号为27017的实例进程 2018 - 07 - 17 t10:33:29.835 + 0800我控制[主要]自动禁用TLS 1.0, force-enable TLS 1.0指定——sslDisabledProtocols‘没有’ 叉子进程,等到服务器准备连接。 分叉的过程:3751 子进程成功开始,父母退出
初始化配置并启动复制集
启动完4个MongoDB实例后,下面介绍如何配置并启动MongoDB复制集。这里先配置包含3个节点的复制集(后面会再进行添加最后一个实例),主要代表主节点.Secondary代表从节点
<代码> # mongod - f/usr/local/mongodb/bin/mongodb2. root@localhost本相依——smallfiles 叉子进程,等到服务器准备连接。 分叉的过程:20207 子进程成功开始,父母退出 # mongod - f/usr/local/mongodb/bin/mongodb3. root@localhost本相依——smallfiles 叉子进程,等到服务器准备连接。 分叉的过程:20230 子进程成功开始,父母退出 # mongod - f/usr/local/mongodb/bin/mongodb4. root@localhost本相依——smallfiles 叉子进程,等到服务器准备连接。 分叉的过程:20253 子进程成功开始,父母退出
可以看到四个实例都已经启动成功,对应的端口号都已经打开。然后进入到端口号为27017端口号的实例中。
<代码> [root@localhost本]# mongo #默认就是端口号为27017的实例
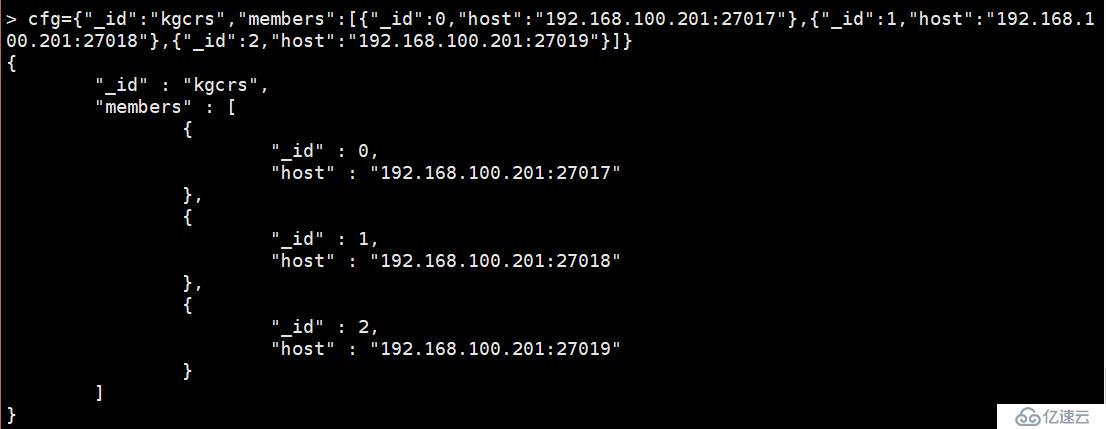
比;cfg={" _id ":“kgcrs”、“成员”:[{" _id ": 0,“主机”:“192.168.100.201:27017”},{“_id”: 1、“主机”:“192.168.100.201:27018 "},{" _id ": 2,“主机”:“192.168.100.201:27019”}]}
#这句代码的意思就是向kgcrs的复制集中添加三个成员
比;rs.initiate (cfg)
{" ok ": 1}
#对复制集进行初始化启动复制集,启动复制集后,可以通过rs.status()查看复制集的完整信息。