
本篇文章为大家展示了怎么在R语言中使用总结()函数,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
R语言是用于统计分析,绘图的语言和操作环境,属于GNU系统的一个自由,免费,源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
总结():获取描述性统计量,可以提供最小值,最大值,四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计等。
<强>结果解读如下:
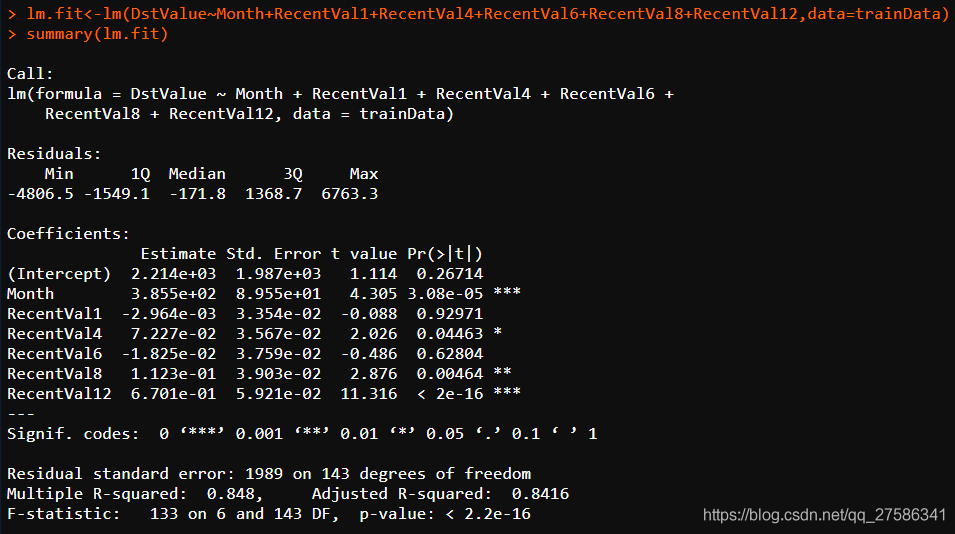
1。调用:叫
当创建模型时,以上代码表明lm是如何被调用的。
2。残差统计量:残差
残差第一四分位数(1 q)和第三分位数(Q3)有大约相同的幅度,意味着有较对称的钟形分布。
3。系数:系数
分别表示:估值标准误差T值p值
拦截:表示截距
月:影响因子/特征
估计的列:包含由普通最小二乘法计算出来的估计回归系数。
性病。错误的列:估计的回归系数的标准误差。
p值估计系数不显著的可能性,有较大p值的变量是可以从模型中移除的候选变量。
t统计量和p值:从理论上说,如果一个变量的系数是0,那么该变量是无意义的,它对模型毫无贡献。
然而,这里显示的系数只是估计,它们不会正好为0。
因此,我们不禁会问:从统计的角度而言,真正的系数为0的可能性有多大?这是t统计量和p值的目的,在汇总中被标记为t值和公关(在| t |)。
其中,我们可以直接通过p值与我们预设的0.05进行比较,来判定对应的解释变量的显著性,我们检验的原假设是:该系数显著为0;若术中,0.05,则拒绝原假设,即对应的变量显著不为0。
可以看到月,RecentVal4, RecentVal8都可以认为是在p为0.05的水平下显著不为0,通过显著性检验;拦截的p值为0.26714,不显著。
4。多个平方和调整平方
这两个值,即R ^{2},常称之为“拟合优度”和“修正的拟合优度”,指回归方程对样本的拟合程度几何,这里我们可以看的到,修正的拟合优度=0.8416,表示拟合程度良好,这个值当然是越高越好。
当然,提升拟合优度的方法很多,当达到某个程度,我们也就认为差不多了。
具体还有很复杂的判定内容,有兴趣的可以看看:http://baike.baidu.com/view/657906.htm
5。F统计量
F统计量,是我们常说的F统计量,也成为F检验,常常用于判断方程整体的显著性检验,其值越大越显著;其p值为假定值:& lt;2.2 e-16显然是& lt; 0.05的,可以认为方程在P=0.05的水平上还是通过显著性检验的。
简单总结:
T检验:检验解释变量的显著性;
平方:查看方程拟合程度;
F检验:是检验方程整体显著性。
如果是一元线性回归方程,T检验的值和F检验的检验效果是一样的,对应的值也是相同的。
<强>补充:在R语言中显示美丽的数据摘要总结统计信息




