
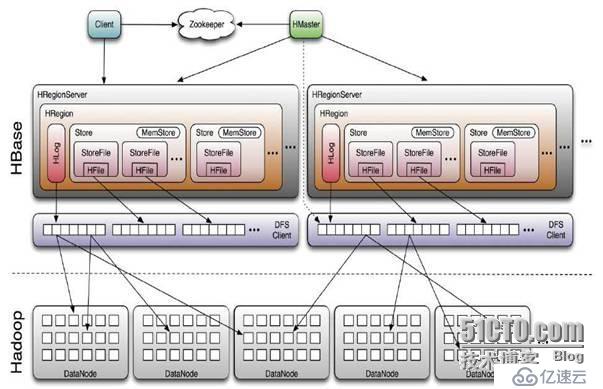
<强> 1。Hbase的集群架构
,,首先hbase是hadoop的一个组件。而hadoop内部有很多的组件,这些组件几乎都依赖于hadoop最核心的两个东西建立起来的,一个是hdfs文件系统,另一个是mapreduce。当然hbase也不例外。
,,hbase其实就是一个非关系型的数据库系统,可以将他和关系型数据库mysql类比一下,可能会便于
理解。
 <李>
<李>
管理员
,,保证任何时候,集群中只有一个运行主
,,存贮所有地区的寻址入口
,,实时监控区域服务器的状态,将区域服务器的上线和下线信息,实时通知给主人
,,存储Hbase的模式,包括有哪些表,每个表有哪些列族
主可以启动多个HMaster,通过管理员的主选举机制保证总有一个主运行
,,为地区服务器分配地区
,,负责区域服务器的负载均衡
,,发现失效的区域服务器并重新分配其上的地区
<强> 2。,<强> Hbase的存储方式和结构
<强>,,强要讲Hbase的存储方式,我们从两方面来描述,一个是逻辑存储方式和物理的存储方式。(比如mysql中的二维关系表就是关系型数据库的逻辑存储结构,而这些表在硬盘上实际的存储形式便是所谓的物理存储方式)。
,,,Hbase的逻辑存储方式:
,,,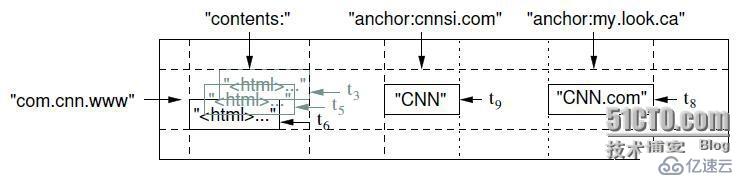 Hbase体系结构理解
Hbase体系结构理解




