
一、数据泵技术的优点
原有的导出和导入技术基于客户机,而数据泵技术基于服务器。默认所有的转储,日志和其他文件都建立在服务器上,以下是数据泵技术的主要优点:
1,改进了性能
2,重新启动作业的能力
3,并行执行的能力
4,关联运行作业的能力
5,估算空间需求的能力
6,操作的网格方式
7,细粒度数据导入功能
8日重映射能力
二、数据泵导出和导入的用途
1,将数据从开发环境转到测试环境或产品环境
2,将数据从开发环境转到测试环境或产品环境
3,在修改重要表之前进行备份
4,备份数据库
5,把数据库对象从一个表空间移动到另一个表空间
6,在数据库直接移植表空间
7,提取表或其他对象的DDL
注意:数据库不建立完备的备份,因为在导出文件中没有灾难发生时的最新数据。但是对于较小的数据库和个别的表空间的导出,数据导出仍然是一个可行的备份工具。
三,数据泵的组成部分
<强>数据泵技术主要有三个以下部件组成:
?DBMS_DATAPUMP程序包。这是驱动数据字段元数据装载和卸载的主要引擎.DBMS_DATAPUMP程序包包括数据泵技术的核心部分,此核心部分以过程的形式出现,实际驱动数据装载和卸载。
?DBMS_METADATA。为了提取并修改元数据,甲骨文提供了DBMS_METADATA程序包。
?命令行客户机。两个实用程序expdp和impdp进行导出和导入工作
四,数据泵文件
<强>对于数据泵转储文件,可以使用三种类型的文件:
?转储文件:此文件存储实际原数据
?日志文件:记录数据泵操作的消息和结果
? SQL文件:数据泵使用一种特殊的参数sqlfile,把导入作业中要执行的所有DDL语句写入一个文件中。数据泵并不实际执行SQL,它仅仅是将DDL语句写入由sqlfile参数制定的文件中。
五、操作
chmod - r 777/opt//根模式下开放/opt文件夹的权限
su - oracle//切换甲骨文用户
mkdir/opt/app/贝克//创建数据泵备份文件目录
sqlplus sysdba//使用管理员身份登录
完成创建目录dump_dir '/opt/app/贝克;#新建目录对象dump_dir,将目录“/opt/app/bak"进行映射
完成创建用户c # #汤姆被abc123 #创建“c # # tom"测试用户并授权
2用户默认表空间
3临时表空间临时
4配额无限alt=凹坠俏氖荼谩?
#导出c # #汤姆用户下的表
解析:
目录#指定其路径映射的别名名称,导出数据的路径
dumpfile #指定转储文件的名称,默认名称为expdat。dmp
表#指定表模式导出
查看导出的数据文件:ls/opt/app/贝克/
<>强导入数据
sqlplus c # #斯科特/abc23 #使用“tom"用户登录
完成删除表信息;#模拟故障删除其中一张表
恢复数据:
impdp c # #汤姆/tom123目录=dump_dir dumpfile=汤姆。dmp表=info #恢复信息表及其数据
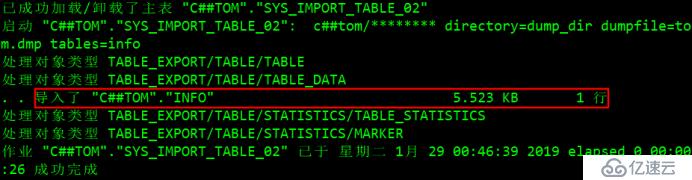 sqlplus c # #汤姆/tom123 #登录“scott"用户
sqlplus c # #汤姆/tom123 #登录“scott"用户
完成选择从user_tables table_name;#查看是否恢复成功
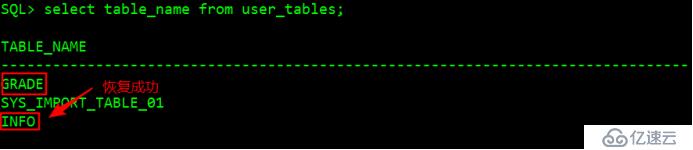
六,总结
<强>数据泵使用EXPDP和IMPDP时应该注意的事项:
1,实验和小鬼是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用。
2, EXPDP和IMPDP是服务端的工具程序,他们只能在甲骨文服务端使用,不能在客户端使用。
3,小鬼只适用于EXP导出的文件,不适用于EXPDP导出文件;IMPDP只适用于EXPDP导出的文件,而不适用于EXP导出文件。
4, EXPDP或IMPDP命令时,可暂不指出用户名/密码@实例作为身名份,然后根据提示再输入,如:
=斯科特dumpfile=EXPDP EXPDP模式。dmp目录=dir;




