
介绍 scrapy startproject CrawlMeiziTu CrawlMeiziTu/,scrapy.cfg
,CrawlMeiziTu/,__init__ . py
items.py才能
pipelines.py才能
settings.py才能
,middlewares.py
蜘蛛才能/,,__init__ . py
,,…
cd CrawlMeiziTu
scrapy genspider Meizitu http://www.meizitu.com/a/list_1_1.html CrawlMeiziTu/,scrapy.cfg
,CrawlMeiziTu/,__init__ . py
items.py才能
pipelines.py才能
settings.py才能
,middlewares.py
蜘蛛才能/Meizitu.py
,,__init__ . py
,,… 得到scrapy import cmdline
cmdline.execute (“scrapy crawl Meizitu" .split ()) , BOT_NAME =, & # 39; CrawlMeiziTu& # 39;,=,SPIDER_MODULES [& # 39; CrawlMeiziTu.spiders& # 39;】=,NEWSPIDER_MODULE & # 39; CrawlMeiziTu.spiders& # 39;
,ITEM_PIPELINES =, {
,& # 39;CrawlMeiziTu.pipelines.CrawlmeizituPipeline& # 39;:, 300年,
,}=,IMAGES_STORE & # 39; D://pic2& # 39;
DOWNLOAD_DELAY 0.3=,=,USER_AGENT & # 39; Mozilla/5.0, (Windows NT 6.1;, Win64;, x64), AppleWebKit/537.36, (KHTML, like 壁虎),Chrome/58.0.3029.110 Safari/537.36 & # 39;=,ROBOTSTXT_OBEY 真正的 #, - *安康;编码:utf-8 - * -
#,Define here 从而models for your scraped 项目
#
#,阅读documentation 在:
#,http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CrawlmeizituItem (scrapy.Item):
,# define 从而fields for your item here 如:
,# name =, scrapy.Field ()
,#标题为文件夹名字=,,title scrapy.Field ()=,,url scrapy.Field ()=,,tags scrapy.Field ()
,#图片的连接=,,src scrapy.Field ()
,# alt为图片名字=,,alt scrapy.Field () #, - *安康;编码:utf-8 - * -
import 操作系统
import 请求
得到CrawlMeiziTu.settings import IMAGES_STORE
class CrawlmeizituPipeline(对象):
,def process_item(自我,,,,蜘蛛):
fold_name 才能=,,,. join(项目[& # 39;标题# 39;])
header 才能=,{
,,& # 39;用户代理# 39;:,& # 39;用户代理:Mozilla/5.0, (Windows NT 6.1;, Win64;, x64), AppleWebKit/537.36, (KHTML, like 壁虎),Chrome/58.0.3029.110 Safari/537.36 & # 39;
,,& # 39;饼干# 39;:,& # 39;b963ef2d97e050aaf90fd5fab8e78633& # 39;
,,#需要查看图片的饼干信息,否则下载的图片无法查看
,,}
时间=images 才能;[]
#才能,所有图片放在一个文件夹下
时间=dir_path 才能;& # 39;{}& # 39;.format (IMAGES_STORE)
if 才能;not os.path.exists (dir_path),以及len(项目[& # 39;src # 39;]), !=, 0:
,,os.mkdir (dir_path)
if 才能len(项目[& # 39;src # 39;]),==, 0:
,,with 开放(& # 39;. .//check.txt& # 39;,, & # 39; a + & # 39;), as 外交政策:
,,,fp.write (““. join(项目[& # 39;标题# 39;]),+,“:“,+,““. join(项目(& # 39;url # 39;)))
,,,fp.write (“\ n")
for 才能;jpg_url,名字,,num 拷贝zip(项目[& # 39;src # 39;],,项目[& # 39;内容# 39;],范围(0100)):
,,file_name =, name +, str (num)
,,file_path =, & # 39; {}//{} & # 39; .format (dir_path, file_name)
,,images.append (file_path)
,,if os.path.exists (file_path),或是os.path.exists (file_name):
,才能继续
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
null
小编给大家分享一下Python怎么使用Scrapy爬虫框架全站爬取图片并保存本地,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获、下面让我们一起去了解一下吧!
基本上按照文档的流程走一遍就基本会用了。
步骤1:
在开始爬取之前,必须创建一个新的Scrapy项目。进入打算存储代码的目录中,运行下列命令:
该命令将会创建包含下列内容的教程目录:
该命令将会创建包含下列内容的教程目录:
我们主要编辑的就如下图箭头所示:
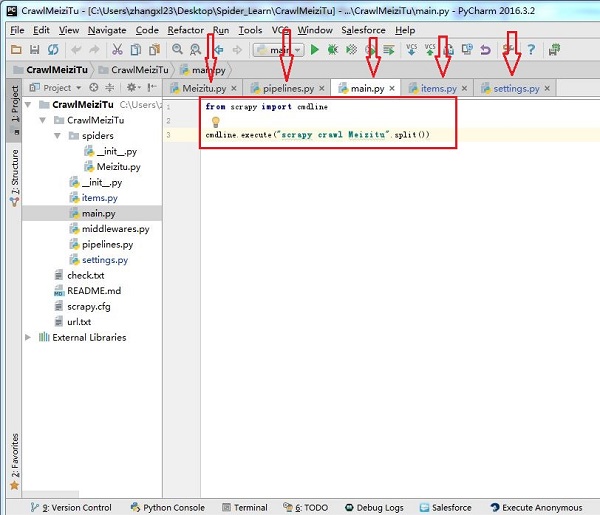
主要。py是后来加上的,加了两条命令,
主要为了方便运行。
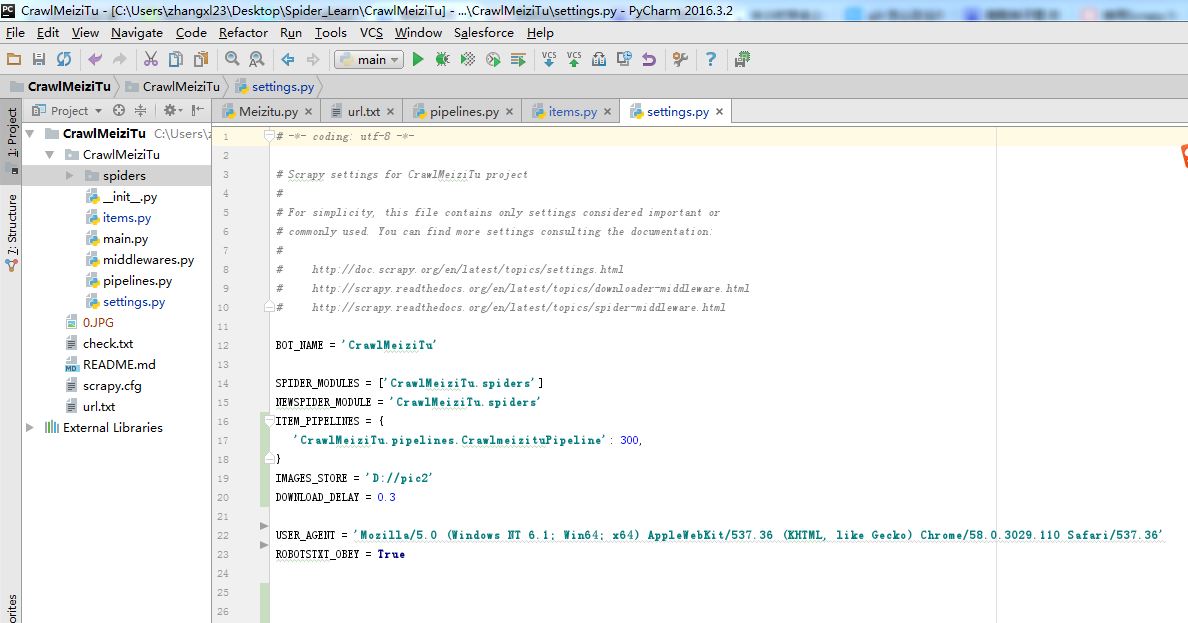
<强>步骤2:编辑设置,如下图所示
主要设置USER_AGENT,下载路径,下载延迟时间
<强>步骤3:编辑物品。
项目主要用来存取通过蜘蛛程序抓取的信息。由于我们爬取妹子图,所以要抓取每张图片的名字,图片的连接,标签等等

<强>目的:编辑管道
管道主要对项目里面获取的信息进行处理,比如说根据标题创建文件夹或者图片的名字,根据图片链接下载图片。




