怎么解决复述,数据过多内存过大问题?针对这个问题,这篇文章给出了相对应的分析和解答,希望能帮助更多想解决这个问题的朋友找到更加简单易行的办法。
<强>复述这个内存数据库,它的高性能,稳定性都是不用怀疑的,但我们塞进复述的数据过多,内存过大,那如果出问题,那它可能会带给我们的就是灾难性。
这几年的线上业务表明,复述,这个内存数据库,它的高性能,稳定性都是不用怀疑的,但我们塞进复述的数据过多,内存过大,那如果出问题,那它可能会带给我们的就是灾难性(我想很多公司都遇到过)这里列举一下,我们遇到的一些问题:
<强>主库宕机,,,,,,
<>强先来看一下主库宕机容灾过程,如下图:
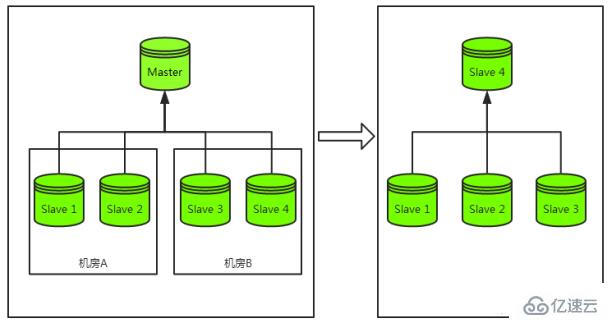
在主库宕机的时候,我们最常见的容灾策略为“切主”。具体为从该集群剩余从库中选出一个从库并将其升级为主库,该从库升级为主库后再将剩余从库挂载至其下成为其从库,最终恢复整个主从集群结构。
以上是一个完整的容灾过程,而代价最大的过程为从库的重新挂载,而非主库的切换。
<强>解决办法
<强>解决办法当然就是极力减少内存的使用了,一般情况下,我们都是这么做的:
<强> 1设置过期时间
对具有时效性的关键设置过期时间,通过复述,自身的过期关键清理策略来降低过期关键对于内存的占用,同时也能够减少业务的麻烦,不需要定期清理了
<强> 2不存放垃圾到复述中
这简直就是废话,但是,有跟我们同病相怜的人么?
<>强3及时清理无用数据
例如一个复述,承载了3个业务的数据,一段时间后有2个业务下线了,那你就把这两个业务的相关数据清理了呗
<强> 4尽量对数据进行压缩
例如一些长文本形式的数据,压缩能够大幅度降低内存占用
<强> 5关注内存增长并定位大容量关键
不管是DBA还是开发人员,你用复述,你就必须关注内存,否则,你其实就是不称职的,这里可以分析复述,实例中哪些关键比较大从而帮助业务快速定位异常关键(非预期增长的钥匙,往往是问题之源)
<强> 6鼠兔
如果实在不想搞的那么累,那就把业务迁移到新开源的鼠兔上面,这样就不用太关注内存了,复述,内存太大引发的问题,那也都不是问题了。
关于解决复述,数据过多内存过大问题的方法就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看的到。