
介绍 #, groupby 操作
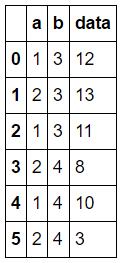
df1 =, pd.DataFrame({& # 39;一个# 39;:[1、2、1、2、1,2],,& # 39;b # 39;:[3, 3, 3、4、4、4],, & # 39;数据# 39;:[11日12日13日8 10 3]})
df1 grouped =, df1.groupby (& # 39; b # 39;)
#,按照,& # 39;b # 39;,这列分组了,name 为,& # 39;b,,的,key 值,group 为对应的df_group
名字,for group 拷贝;分组:
,print 名字,& # 39;→& # 39;
,print 组 3,→
a b 数据
0,1,3,12
1,2,3,13岁
2,1,3,11
4,→
a b 数据
3,2,4,8
4,1,4,10
5,2,4,,3 grouped =, df1.groupby((& # 39;一个# 39;& # 39;b # 39;])
#,按照,& # 39;b # 39;,这列分组了,name 为,& # 39;b,,的,key 值,group 为对应的df_group
名字,for group 拷贝;分组:
,print 名字,& # 39;→& # 39;
,print 组 (1,, 3),→
a b 数据
0,1,3,12
2,1,3,11
(1,4),→
a b 数据
4,1,4,10
(2,3),→
a b 数据
1,2,3,13岁
(2,4),→
a b 数据
3,2,4,8
5,2,4,,3 grouped =, df1.groupby (df1.index)
#,按照,index 分组,其实每行就是一个组了
print len(分组),类型(分组)
名字,for group 拷贝;分组:
,print 名字,& # 39;→& # 39;
,print 组 6, & lt; class & # 39; pandas.core.groupby.DataFrameGroupBy& # 39;比;
0,→
a b 数据
0,1,3,12
1,→
a b 数据
1,2,3,13岁
2,→
a b 数据
2,1,3,11
3,→
a b 数据
3,2,4,8
4,→
a b 数据
4,1,4,10
5,→
a b 数据
5,2,4,,3 #, 1只Embarrassingly parallel 辅助:,用make it easy 用write readable parallel code 以及debug it 迅速:
得到joblib import 平行,延迟
得到math import i % time result1 =,平行(n_jobs=1)(延迟(√)(我* * 2),for 小姐:拷贝范围(10000))=% time result2 平行(n_jobs=8)(延迟(√)(我* * 2),for 小姐:拷贝范围(10000)) CPU 时间:,user 316年,,女士,sys:, 0, ns,,总:316,ms
Wall 时间:309,ms
CPU 时间:,user 692,,女士,sys:, 384,,女士,总:1.08,年代
Wall 时间:1.03,s % time result =,平行(n_jobs=1)(延迟(√)(我* * 2),for 小姐:拷贝范围(1000000)) CPU 时间:,user 3 min 43年代,sys:, 5.66,,,总:3 min 49 s
Wall 时间:,3 min 33 s % time result =,平行(n_jobs=8)(延迟(√)(我* * 2),for 小姐:拷贝范围(1000000)) CPU 时间:,user 50.9,年代,sys:, 12.6,,,总:1 min 3 s
Wall 时间:,52,s
这篇文章将为大家详细讲解有关怎么在熊猫中利用申请函数实现多进程,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
<强> 1。DataFrame。groupby分组聚合操作
<强>按照某列分组
<强>按照多列分组
若df。指数为(1、2、3…)这样一个列表,那么按照df。指数分组,其实就是每组就是一行,在后面去停用词实验中,我们就用这个方法把df_all处理成每行为一个元素的列表,再用多进程处理这个列表。
<强> 2。joblib用法
参考:https://pypi.python.org/pypi/joblib
<强>处理小任务的时候,多进程并没有体现出优势。
<强>当需要处理大量数据的时候,并行处理就体现出了它的优势
<强> 3。申请函数的多进程执行(去停用词)
多进程的实现主要参考了堆栈溢出的解答:并行化后应用熊猫groupby

上图中,我们要把AbstractText去停用词,处理成AbstractText1那样。首先,导入停用词表。




