介绍
本篇文章为大家展示了Python中字典和列表性能的对比分析,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
Python列表和字典
<李> 前面我们了解了“大O表示法”以及对不同的算法的评估,下面来讨论下Python两种内置数据类型有关的各种操作的大O数量级:列表列表和字典dict .
<李> 这是Python中两种非常重要的数据类型,后面会用来实现各种数据结构,通过运行试验来估计其各种操作运行时间数量级。
对比列表和dict操作如下:

列表列表数据类型常用操作性能:
最常用的是:按索引取值和赋值(v=[我],[我]=v),由于列表的随机访问特性,这两个操作执行时间与列表大小无关,均为O (1)。
另一个是列表增长,可以选择append()和“+”:lst.append (v),执行时间是O (1), lst=lst + [v],执行时间是O (n + k),其中k是被加的列表长度,选择哪个方法来操作列表,也决定了程序的性能。
测试4种生成n个整数列表的方法:

创建一个定时器对象,指定需要反复运行的语句和只需要运行一次的“安装语句“。
然后调用这个对象的时间方法,指定反复运行多少次。
#,计时器(支撑=皃ass",,设置=皃ass"),,, #,这边只介绍两个参数
:#,支撑声明的缩写,就是要测试的语句,要执行的对象
#,设置:导入被执行的对象(就和运行代码前,需要导入包一个道理),在主程序命名空间中,,导入
时间=time1 计时器(“test1(),,,,得到__main__ import test1"),
打印(“concat: {}, seconds" .format (time1.timeit (1000)))
时间=time2 计时器(“test2(),,,,得到__main__ import test2")
打印(“附加:{},seconds" .format (time2.timeit (1000)))
time3 =,计时器(“test3(),,,,得到__main__ import test3")
打印(“理解:{},seconds" .format (time3.timeit (1000)))
时间=time4 计时器(“test4(),,,,得到__main__ import test4")
print (“list 范围:{},seconds" .format (time4.timeit (1000) 结果如下:

可以看的到,4种方法运行时间差别挺大的,列表连接(concat)最慢,列表范围最快,速度相差近100倍.append要比concat快得多。另外,我们注意到列表推导式速度大约是追加两倍的样子。
总结列表基本操作的大O数量级:
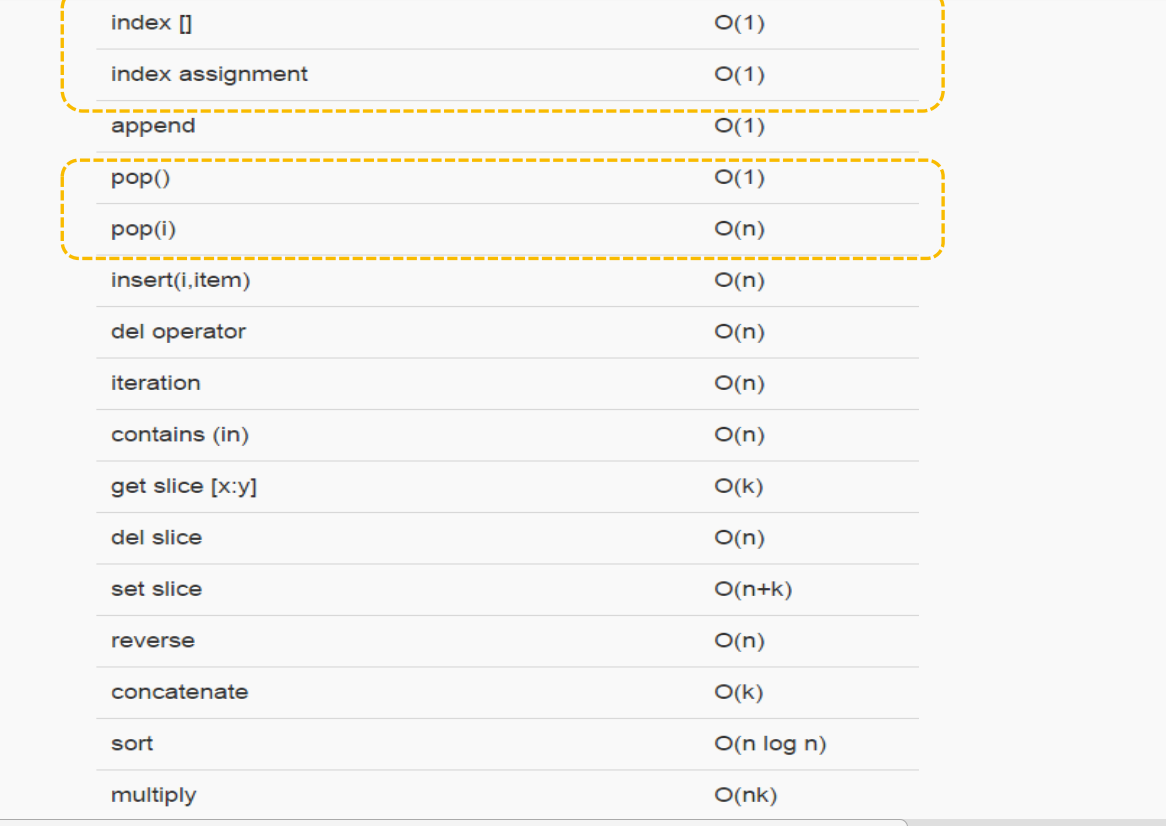
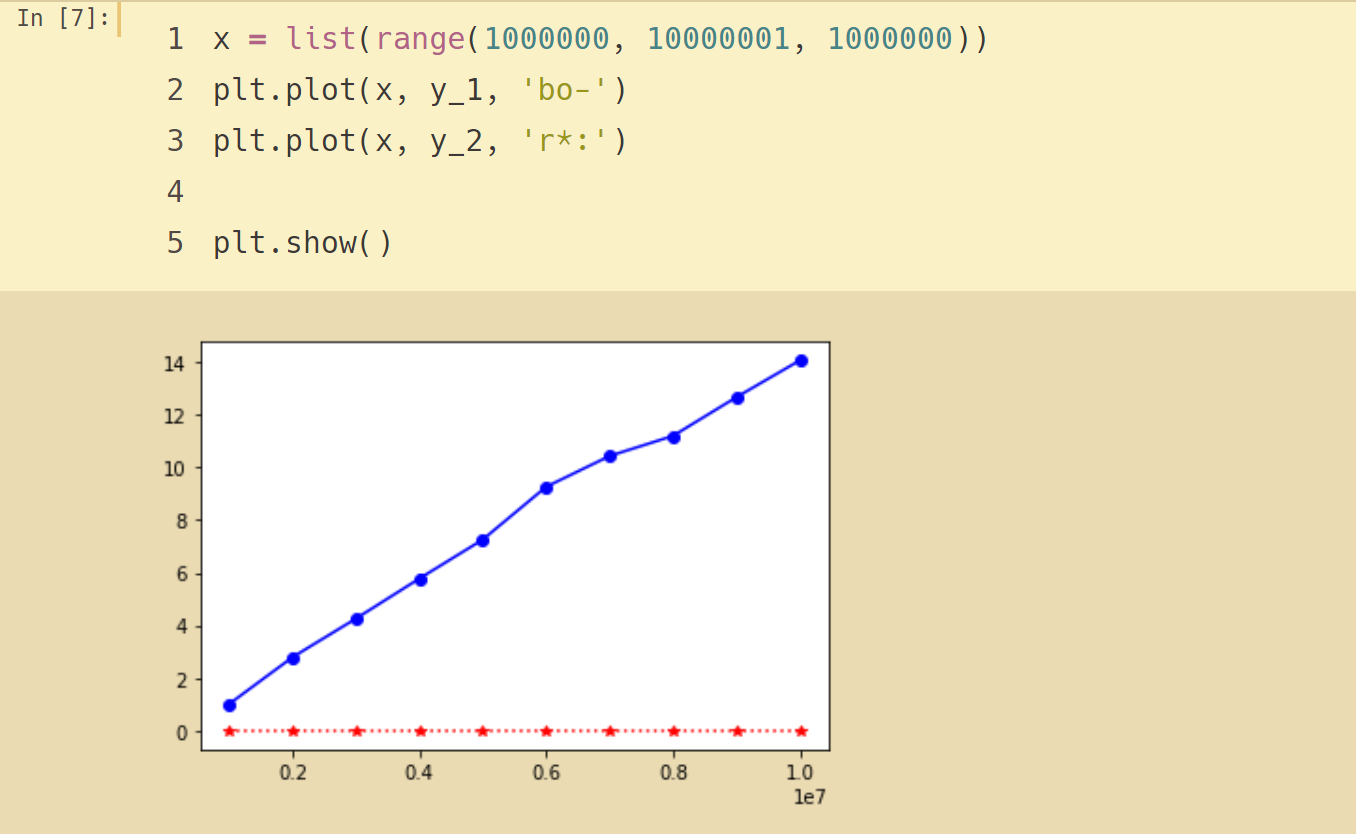
我们注意到流行这个操作,pop()是从列表末尾移除元素,时间复杂度为O(1),流行(i)从列表中部移除元素,时间复杂度为O (n)。
原因在于Python所选择的实现方法,从中部移除元素的话,要把移除元素后面的元素,全部向前挪位复制一遍,这个看起来有点笨拙
但这种实现方法能够保证列表按索引取值和赋值的操作很快,达到O(1)。这也算是一种对常用和不常用操作的折中方案。
list.pop()的计时试验,通过改变列表的大小来测试两个操作的增长趋势:
import 时间
时间=pop_first timeit.Timer (“x.pop(0),,,,得到__main__ import x")
时间=pop_end timeit.Timer (“x.pop(),,,,得到__main__ import x")
print(“流行(0),,,,,,,,,,pop ()“)
时间=y_1 []
时间=y_2 []
for 小姐:拷贝范围(1000000,,10000001,,1000000):
,,,x =,列表(范围(i))
,,,p_e =, pop_end.timeit(数量=1000)
,,,x =,列表(范围(i))
,,,p_f =, pop_first.timeit(数量=1000)
,,,print (“{: .6f},,,,,,,, {: .6f}“.format (p_f, p_e))
,,,y_1.append (p_f)
,,,y_2.append (p_e) 结果如下:
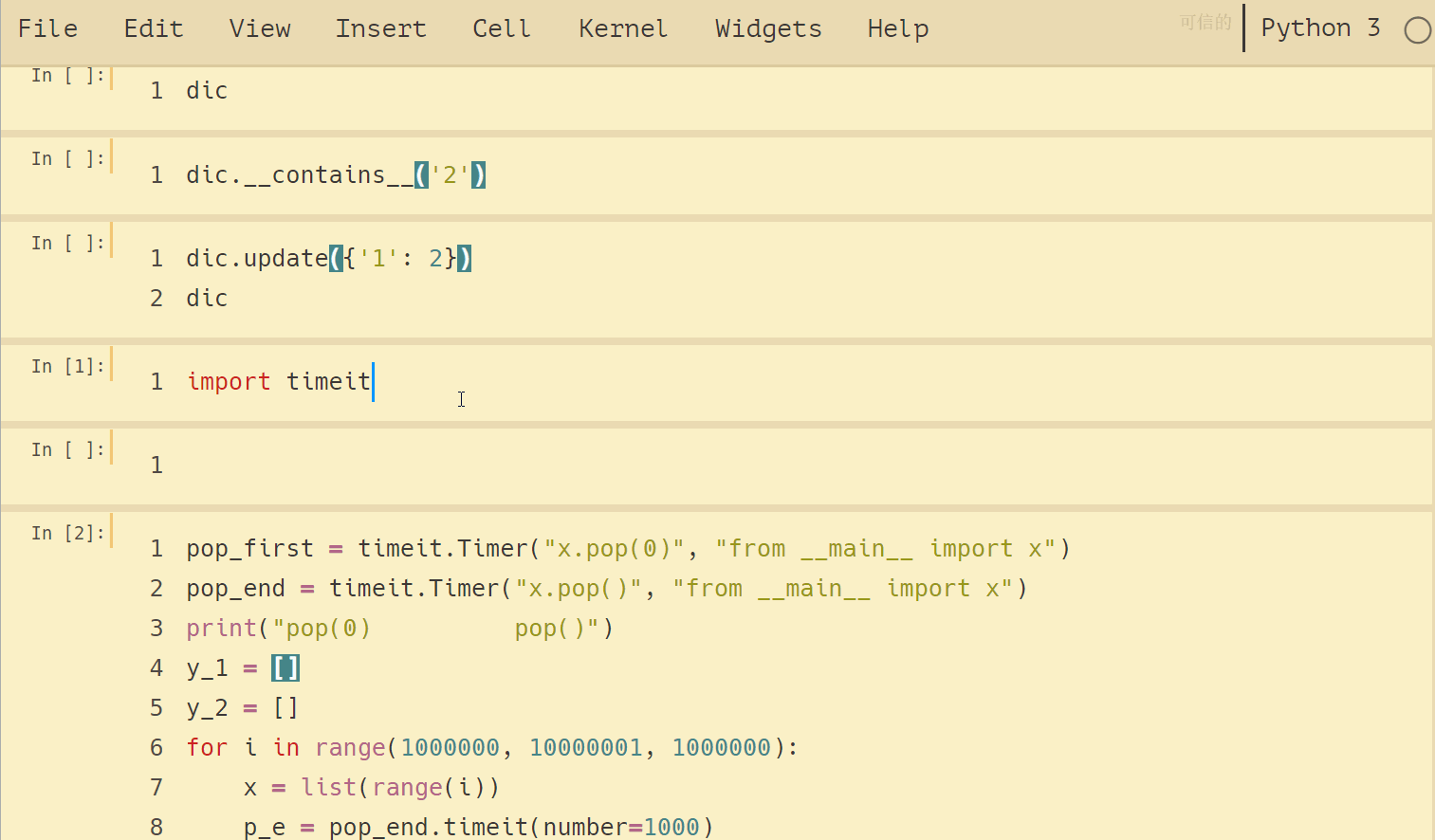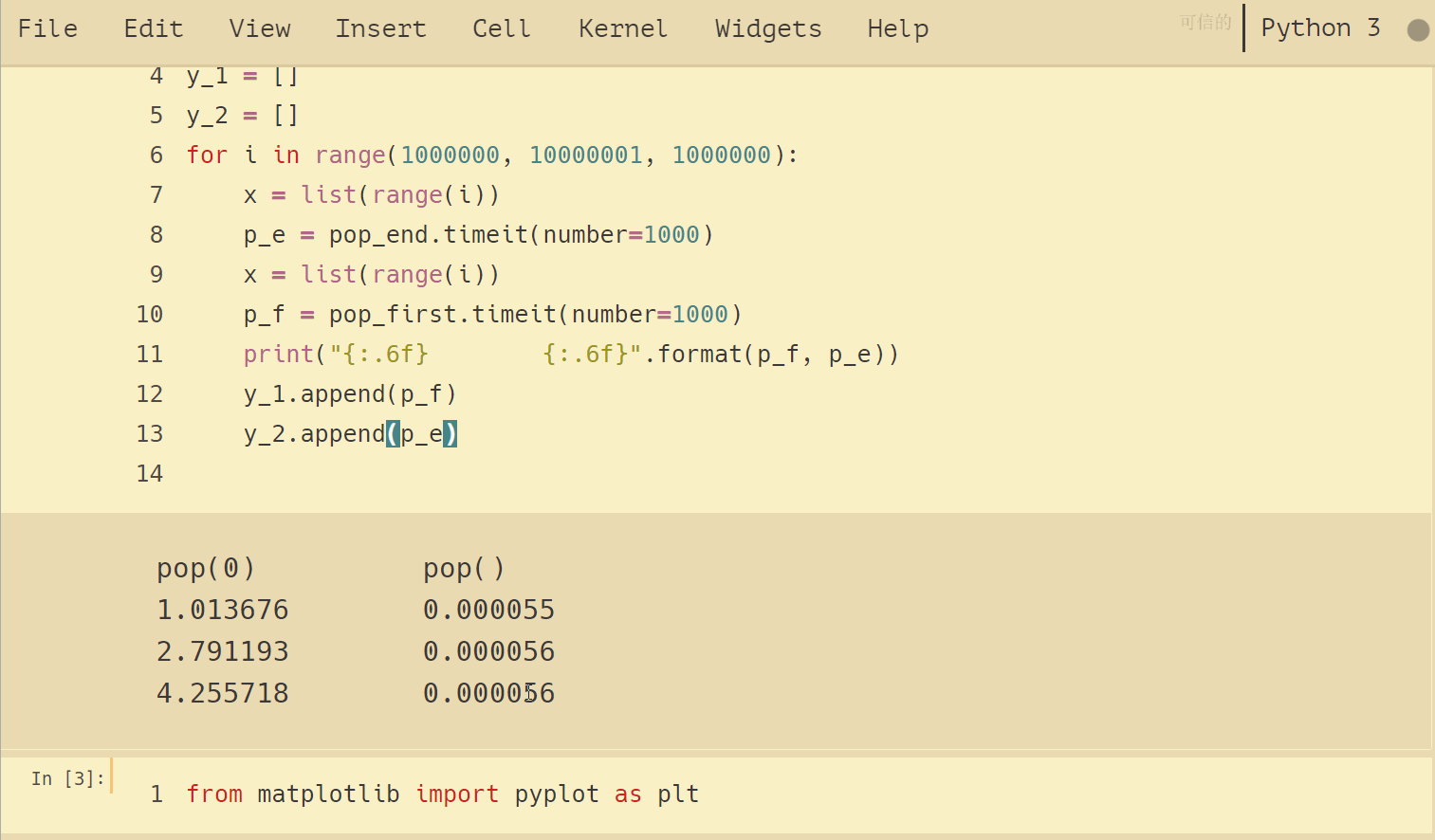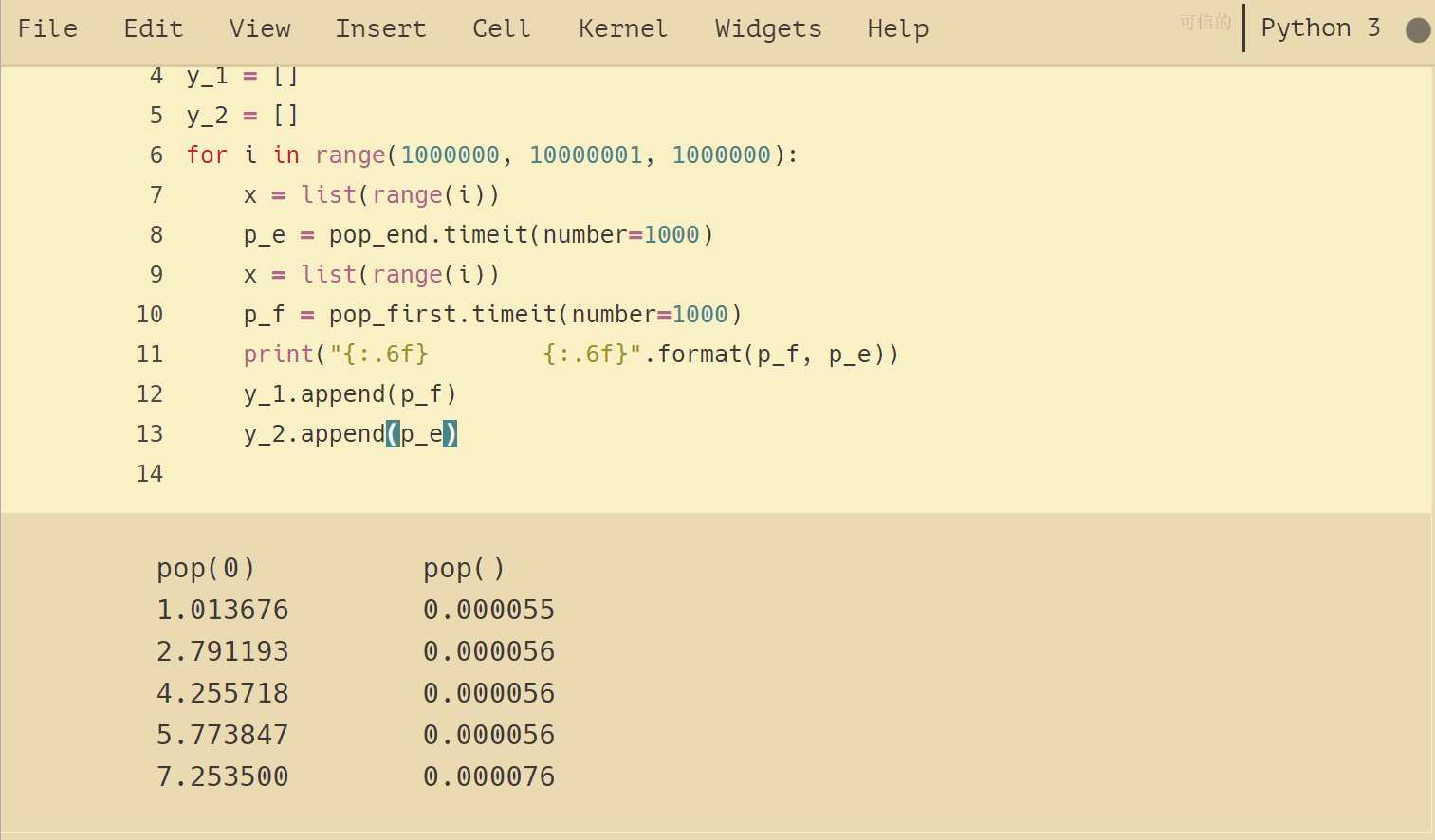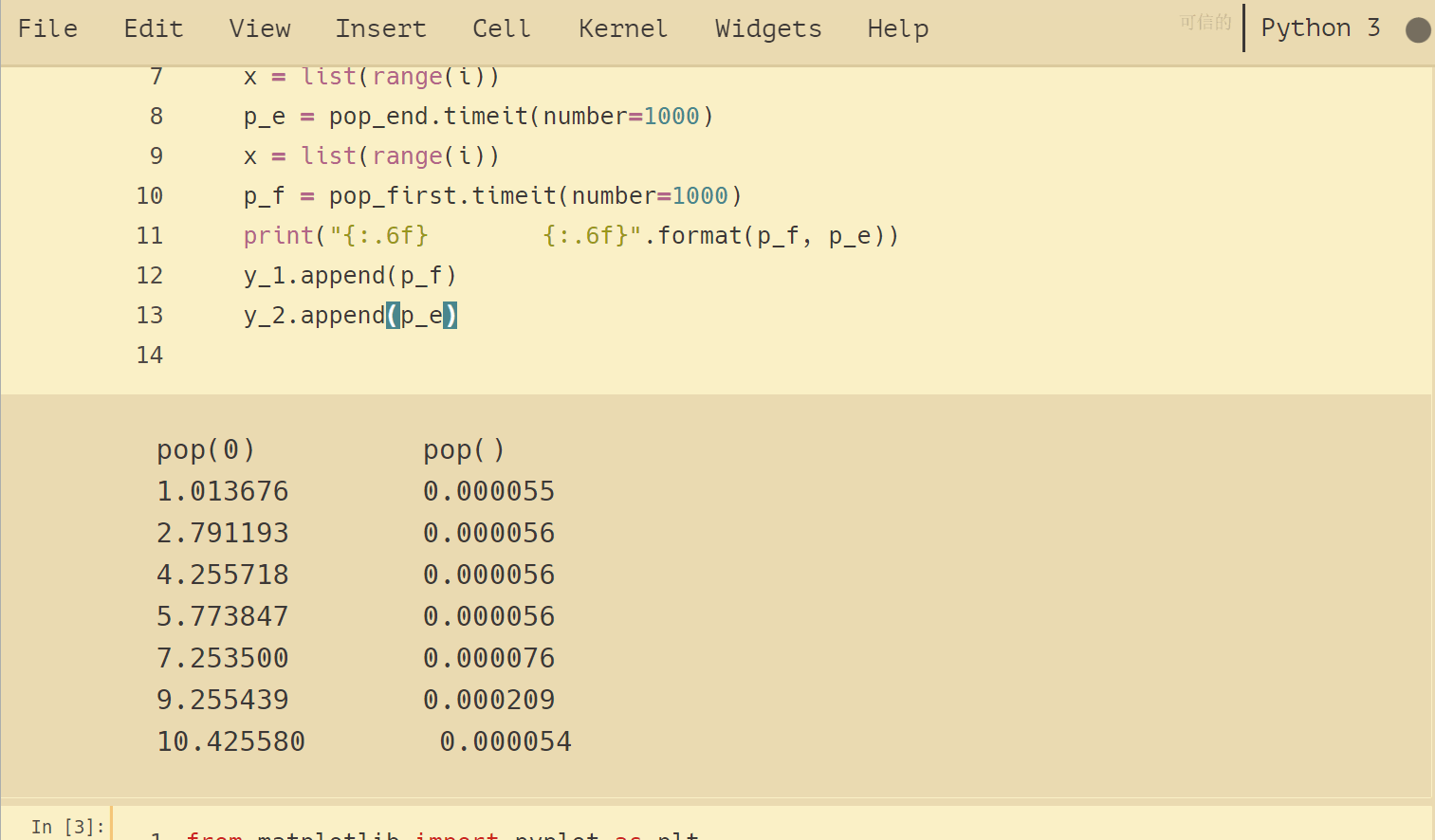
将试验结果可视化,可以看出增长趋势:pop()是平坦的常数,流行(0)是线性增长的趋势。