
小编给大家分享一下Python如何实现资讯算法,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获、下面让我们一起去了解一下吧!
<强>一、概述
资讯(K -最近邻)算法是相对比较简单的机器学习算法之一,它主要用于对事物进行分类。用比较官方的话来说就是:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。为了更好地理解,通过一个简单的例子说明。
我们有一组自拟的关于电影中镜头的数据:
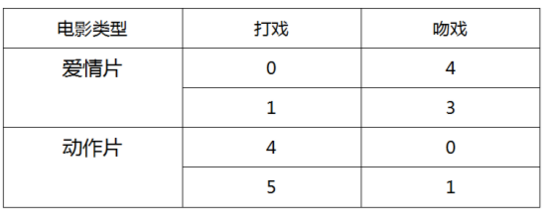
那么问题来了,如果有一部电影,X,它的打戏为3,吻戏为2。那么这部电影应该属于哪一类?
我们把所有数据通过图表显示出来(圆点代表的是自拟的数据,也称训练集;三角形代表的是,X 电影的数据,称为测试数据):
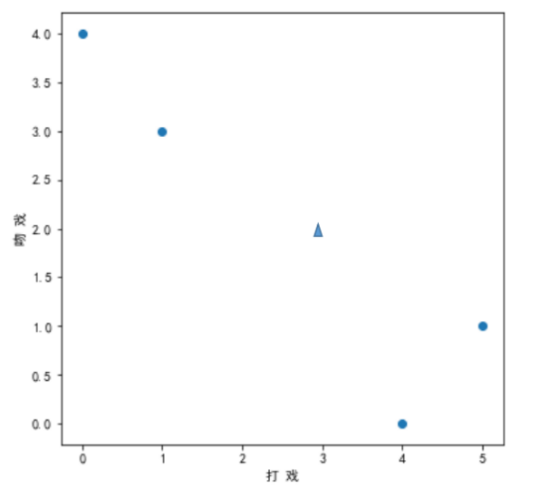
计算测试数据到训练数据之间的距离,假设,k 为3,那么我们就找到距离中最小的三个点,假,如3个点中,有2个属于动作片,1,个属于爱情片,那么把该电影,X 分类为动作片。这种通过计算距离总结k 个最邻近的类,按照”少数服从多数”原则分类的算法就为,资讯(K -近邻)算法。
<强>二,算法介绍
还是以上面的数据为例,打戏数为,X,吻戏数为,y,通过欧式距离公式计算测试数据到训练数据的距离,我上中学那会儿不知道这个叫做欧式距离公式,一直用“两点间的距离公式”来称呼这个公式: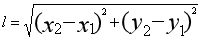 & # 39; & # 39; & # 39;
trainData 才能,安康;训练集
testData 才能,安康;测试集
labels 才能,安康;分类
& # 39;& # 39;& # 39;
def 资讯(trainData, testData,,标签,k):
#才能,计算训练样本的行数
时间=rowSize 才能;trainData.shape [0]
#才能,计算训练样本和测试样本的差值
diff 才能=,np.tile (testData,, (rowSize, 1)),安康;trainData
#才能,计算差值的平方和
时间=sqrDiff 才能;diff * *, 2
时间=sqrDiffSum 才能;sqrDiff.sum(轴=1)
#才能,计算距离
时间=distances 才能;sqrDiffSum 0.5 * *,
#,才能对所得的距离从低到高进行排序
时间=sortDistance 才能;distances.argsort ()
,,
count 才能=,{}
,,
for 才能小姐:拷贝范围(k):
,,,vote =,标签(sortDistance[我]]
,,,计数(投票),=,count.get(投票,,0),+ 1
#,才能对类别出现的频数从高到低进行排序
时间=sortCount 才能;排序(count.items(),,关键=operator.itemgetter(1),反向=True)
,,
#,才能返回出现频数最高的类别
return 才能sortCount [0] [0]
& # 39; & # 39; & # 39;
trainData 才能,安康;训练集
testData 才能,安康;测试集
labels 才能,安康;分类
& # 39;& # 39;& # 39;
def 资讯(trainData, testData,,标签,k):
#才能,计算训练样本的行数
时间=rowSize 才能;trainData.shape [0]
#才能,计算训练样本和测试样本的差值
diff 才能=,np.tile (testData,, (rowSize, 1)),安康;trainData
#才能,计算差值的平方和
时间=sqrDiff 才能;diff * *, 2
时间=sqrDiffSum 才能;sqrDiff.sum(轴=1)
#才能,计算距离
时间=distances 才能;sqrDiffSum 0.5 * *,
#,才能对所得的距离从低到高进行排序
时间=sortDistance 才能;distances.argsort ()
,,
count 才能=,{}
,,
for 才能小姐:拷贝范围(k):
,,,vote =,标签(sortDistance[我]]
,,,计数(投票),=,count.get(投票,,0),+ 1
#,才能对类别出现的频数从高到低进行排序
时间=sortCount 才能;排序(count.items(),,关键=operator.itemgetter(1),反向=True)
,,
#,才能返回出现频数最高的类别
return 才能sortCount [0] [0]
ps: np。瓷砖(testData (rowSize 1)),是将testData 这个数据扩展为,rowSize 列,这样能避免运算错误;
排序(count.items(),关键=operator.itemgetter(1)反向=True),排序函数,里面的参数键=operator.itemgetter(1)反向=True 表示按照,count 这个字典的值(值)从高到低排的序,如果把1,换成0,则是按字典的键(关键)从高到低排序。把,True 换成,False 则是从低到高排序。




