
1,介绍
<代码>在InnoDB启动时,如果是新建数据库则需初始化库,需要创建字典管理的相关信息。函数innobase_start_or_create_for_mysql调用dict_create完成此功能,即创建数据字典,因为InnoDB系统表的个数结构固定,所以初始化库的时候只需要创建这几个表的B +树即可并将B +树的根页号存放到固定位置。对于B +树,只要找到根页面,就可以从根页面开始检索数据。相关系统表(即上一节讲到的4个系统表)在InnoDB内部,不会暴露给用户。 4个系统表通过固定的硬编码进行构建。具体原理流程如下。
2,数据字典创建及加载原理流程
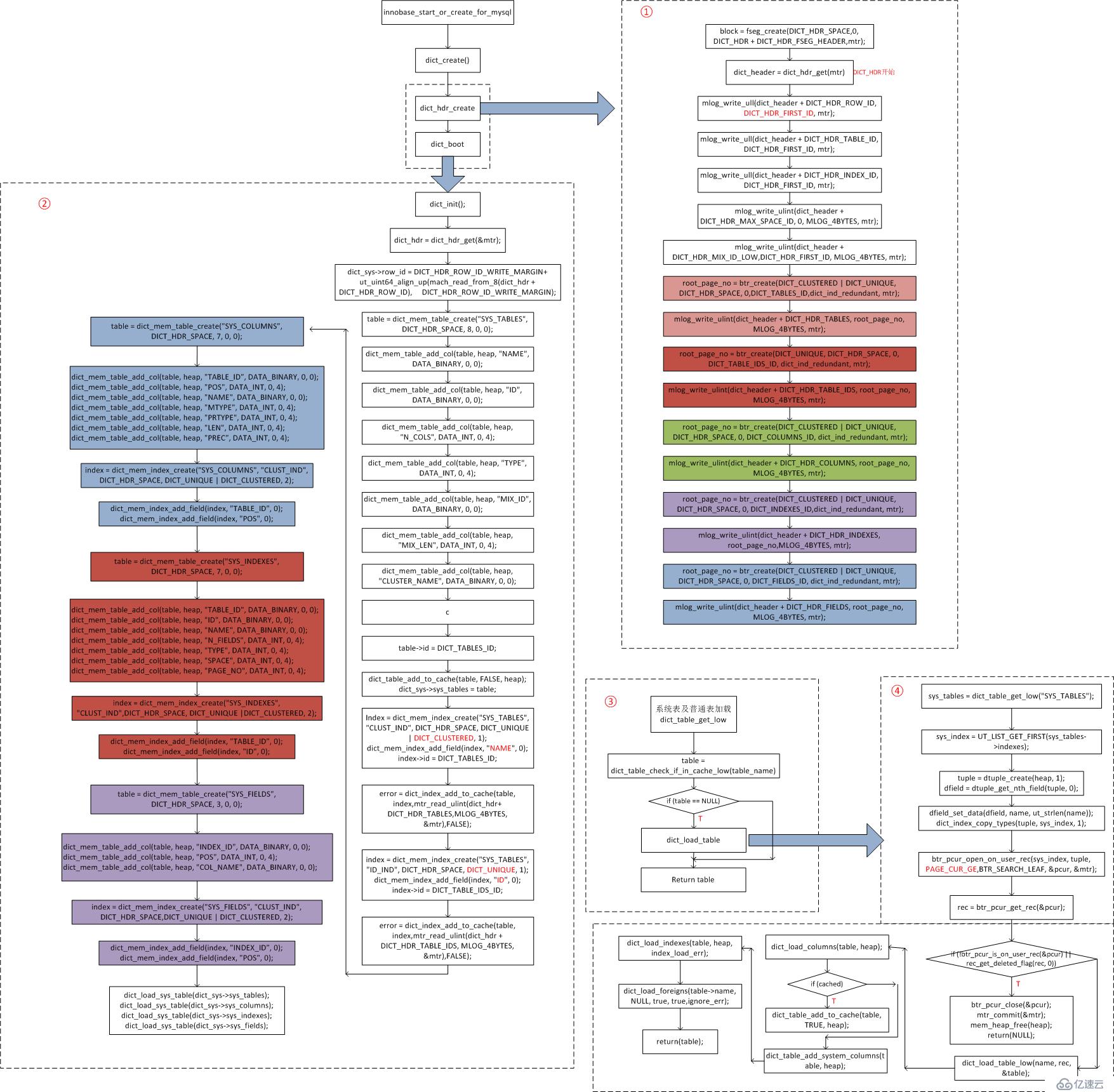 InnoDB数据字典——字典表加载
InnoDB数据字典——字典表加载




