
<强> 1。什么是持久化
复述的所有数据保存在内存中,对数据的更新将异步的保存到硬盘上
<强> 2。持久化的实现方式
快照:某时某刻数据的一个完成备份,,mysql的转储,,复述的RDB写日志:任何操作记录日志,要恢复数据,只要把日志重新走一遍即可,,mysql的Binlog,,-Hhase的HLog,,复述的AOF
<强> 1。什么是RDB
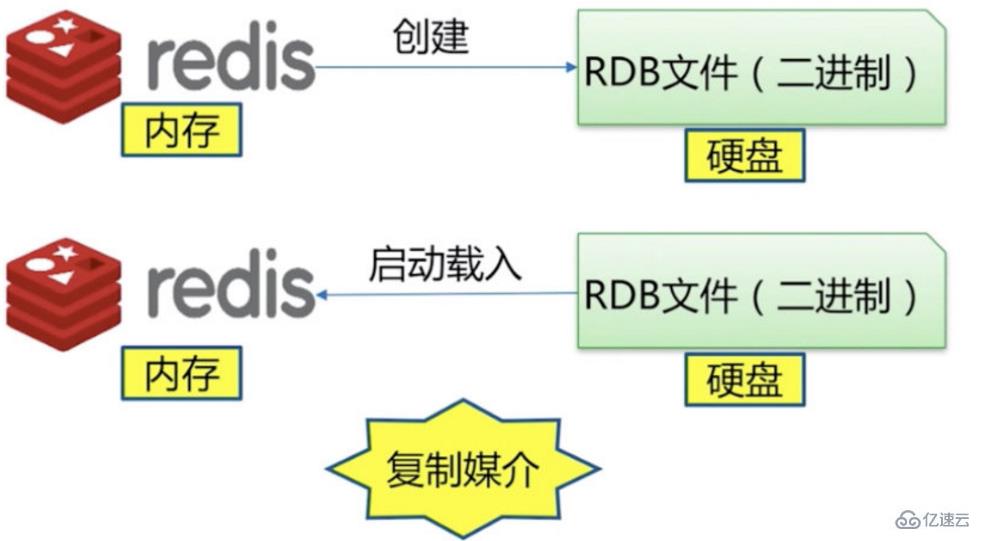
2。触发机制,主要三种方式
第一种:保存(同步)
1客户端输入救命令- - - - -》复述,服务端- - - - -》同步创建RDB二进制文件
2会造成复述的阻塞(数据量非常大的时候)
3文件策略:如果老的RDB存在,会替换老的
4复杂度o (n)
第二种:bgsave(异步,背景储蓄开始)
1客户端输入救命令- - - - -》复述,服务端- - - - -》异步创建RDB二进制文件(叉函数生成一个子进程(叉会阻塞reid),执行createRDB,执行成功,返回给里德消息)
2此时访问复述,会正常响应客户端
3文件策略:跟保存相同,如果老的RDB存在,会替换老的
4复杂度o (n)
第三种:(常用方式)(* * * * * *)自动(通过配置文件)
配置,秒,修改
保存,900年,,,1节约大敌;300年,,,10救大敌;60,,,,10000年如果60年代中改变了1 w条数据,自动生成rdb
如果300年代中改变了10条数据,自动生成rdb
如果900年代中改变了1条数据,自动生成rdb以上三条符合任意一条,就自动生成rdb、内部使用bgsave
#配置:
节省900 1 #配置一条
保存300 10 #配置一条
保存60 10000 #配置一条
dbfilename转储。rdb, # rdb文件的名字,默认为转储。rdb
dir。/# rdb文件存在当前目录
stop-writes-on-bgsave-error是的#如果bgsave出现错误,是否停止写入,默认为是的
rdbcompression #采用压缩格式
rdbchecksum是的#是否对rdb文件进行校验和检验
#最佳配置
节省900 1
节省300 10
保存60 dbfilename转储- 10000}{港口。rdb
#以端口号作为文件名,可能一台机器上很多里德,不会乱
dir/bigdiskpath #保存路径放到一个大硬盘位置目录
stop-writes-on-bgsave-error是的
#出现错误停止
rdbcompression是的#压缩
rdbchecksum是的#校验
rdb触发机制一般使用第三种方式,但是这种方式也会有缺点。如果修改的条数没有在设置范围内那么就不会触发,就会引发很多数据没有持久化的情况,所以我们一般采用下面方式:AOF。
<>强如果是保存不重要的数据可以使用rdb方式(比如缓存数据),如果是保存很重要的数据就要使用AOF,但是两种方式也可以同时使用。
<强>三,AOF
1. rdb问题
耗时,耗性能。不可控,可能会丢失数据。
2. AOF介绍
客户端每写入一条命令,都记录一条日志,放到日志文件中,如果出现宕机,可以将数据完全恢复
3。AOF的三种策略
日志不是直接写到硬盘上,而是先放在缓冲区,缓冲区根据一些策略,写到硬盘上
#第一种:总是:复述——》写命令刷新的缓冲区- - -》每条命令fsync到硬盘- - -》AOF文件
#第二种:everysec(默认值):复述——》写命令刷新的缓冲区- - -》每秒把缓冲区fsync到硬盘——》AOF文件
#第三种:没有:复述——》写命令刷新的缓冲区- - -》操作系统决定,缓冲区fsync到硬盘——》AOF文件
<>强命令 <强>总是 <强> everysec <强>没有强优点不丢失数据,,
每秒一次fsync,丢失1秒数据不用管,
缺点,,
IO开销大,一般的萨塔盘只有几百TPS丢1秒数据不可控4。AOF重写
随着命令的逐步写入,并发量的变大,AOF文件会越来越大,通过AOF重写来解决该问题
<强>原生AOF <强> AOF重写设置你好world
设置你好java
设置你好hehe
增加counter
ncr counter
rpush mylist a
rpush mylist b
rpush mylist c
过期数据
设置你好hehe
设置计数器2 & lt; br/祝辞
rpush mylist a b c
本质就是把过期的,无用的,重复的,可以优化的命令,来优化这样可以减少磁盘占用量,加速恢复速度
实现方式
bgrewriteaof:客户端向服务端发送bgrewriteaof命令,服务端会起一个叉进程,完成AOF重写
复述的持久化介绍




